Vorwort

Ich scheine schon immer die Tendenz gehabt zu haben, mich selbst als Maschine zu betrachten, mich oft aus der Perspektive eines Außenstehenden zu beobachten, verschiedene Module zu integrieren und ständig zu basteln und zu optimieren. Wenn sich ein bestimmtes Verhaltensmuster oder eine Gewohnheit, die ich aufgebaut habe, plötzlich in einem bestimmten Moment als nützlich erweist, empfinde ich ein Gefühl der Freude. Umgekehrt, wenn äußere Einflüsse oder mein eigener Zustand das System stören, erlebe ich ein tiefes Unbehagen durch den Zusammenbruch der Ordnung.
Als Enthusiast für Effizienzwerkzeuge kann man sagen, dass mein persönliches Wissensmanagement und Informationsmanagement der wichtigste Teil meiner selbst ist. Eigentlich hatte ich nicht die Absicht, diesen Artikel zu schreiben, da es zu viele Vorläufer und Praktiken vor mir gibt, und ich nur kleine Anpassungen und Optimierungen basierend auf der Arbeit anderer vornehme. Oft fehlt mir das Selbstvertrauen, dies zu teilen, aber diese Woche habe ich mein Wissensmanagement-System neu aufgebaut und optimiert, und ich bin sehr zufrieden damit. Ich hatte den Drang, es zu dokumentieren, und obwohl ich es ursprünglich nur kurz in meinem Wochenbericht erwähnen wollte, konnte ich nicht aufhören zu schreiben. So entstand dieser Artikel.
Tatsächlich habe ich in meinen Wochenberichten schon oft über Informationsoutput gesprochen, daher wird dieser Artikel auch einige frühere Inhalte abdecken und schließlich die Teile über Informationsbeschaffung und Wissensmanagement ergänzen. Es wird als umfassende Sammlung dienen. Bezüglich der theoretischen Aspekte, wie der “Feynman-Lerntechnik” und der “Luhmann’schen Zettelkasten-Methode”, gibt es bereits viele ausgezeichnete einführende Artikel, daher werde ich hier keinen Platz für deren Vorstellung verwenden. Stattdessen werde ich mich mehr darauf konzentrieren, die Softwaretools zu beschreiben, die ich in der Praxis verwende, in der Hoffnung, dass es für alle hilfreich sein wird.
Informationsbeschaffung und -management
Ich bin mir nicht sicher, wann es begann, aber ich kann deutlich meine Abhängigkeit von Informationen aus der Online-Welt spüren. Vielleicht ist es anders als bei Spielsucht oder dem oft kritisierten Kurzvideoalgorithmus “Opium”, meine Abhängigkeit ist kein mechanisches Scrollen oder eine Flucht vor Angst, sondern ein Verlangen nach Informationsbeschaffung, das sich sogar zu einer Lebensweise internalisiert hat. Da ich Vertrauen in meine Fähigkeit habe, Informationen zu filtern und zu verdauen, habe ich tatsächlich nicht viel Aufwand für Eingabequellen und Organisation betrieben.
Allerdings, als ich mit immer mehr Bereichen in Berührung kam und mich dafür interessierte, haben sich Informationen kontinuierlich angesammelt. Manchmal hat allein das Durchblättern und Lesen all dessen meine Gedächtniskapazität überschritten. Oft sind diese Informationen in meinen Notizen oder in irgendeiner Ecke meines Geistes verstreut und sind nicht zu einem internalisierten Teil von mir geworden. Es ist auch schwierig, sie später abzurufen oder wiederzufinden. Also habe ich meine Methode der Informationsbeschaffung neu überdacht.
Klassifizierung der Informationsquellen
Meine Informationsquellen lassen sich grob in folgende Kategorien einteilen:
- Zufällige Gedanken
- Informationsfluss
- Fokussiertes Lesen
Zufällige Gedanken

Im täglichen Leben, bei der Arbeit, beim Studium oder in irgendeinem zufälligen Moment habe ich manchmal zufällige Gedanken, die nichts mit dem zu tun haben, was ich gerade tue, oder die Fantasieflüge sind, aber irgendwann in der Zukunft nützlich sein könnten. Da ich selten für längere Zeit von meinem Computer entfernt bin, notiere ich diese normalerweise in Logseqs Journal. Manchmal schicke ich sie vielleicht vorübergehend an eine WeChat-Gruppe mit nur mir selbst darin oder an Telegrams Gespeicherte Nachrichten und füge sie später zu Logseq hinzu.
Informationsfluss
Von dem Moment an, in dem ich jeden Tag aufwache, bin ich von Informationsflüssen verschiedener Plattformen umgeben. Sich auf die Online-Welt zu verlassen, beinhaltet zwangsläufig den Kampf mit sozialen Medien und Algorithmen. Einerseits müssen wir vermeiden, von übermäßigen angsterzeugenden Informationen oder dem “Peer Pressure” aus unseren sozialen Kreisen belastet zu werden. Andererseits müssen wir auch vorsichtig sein mit den von Algorithmen konstruierten Informationskokons. Um ehrlich zu sein, ist das ziemlich schwierig zu erreichen. Selbst wenn ich mehr oder weniger die Fähigkeit habe, mich zurückzuhalten und Informationen zu filtern, und bewusst versuche, dies zu tun, ist es immer noch schwer zu vermeiden, dass meine Gedanken dadurch gestört oder gelenkt werden.
Schließlich habe ich einen einfachen, aber effektiven Ansatz gewählt - ich habe den WeChat Moments-Eingang und die meisten App-Benachrichtigungen ausgeschaltet und die Anzahl der Follows auf Plattformen, die hauptsächlich für die Informationsbeschaffung und nicht für soziale Interaktion gedacht sind (wie Bilibili, Weibo usw.), auf unter 100 begrenzt. Wenn ich neue hinzufüge, filtere und optimiere ich die vorherigen Follows, um irrelevante Inhaltsinterferenzen zu reduzieren. Basierend auf diesen Maßnahmen verwende ich RSS-Abonnements, was etwas altmodisch erscheinen mag, aber ich abonniere nur weniger als 50 Websites, von denen die meisten Blogs oder persönliche Websites sind, und ich filtere sie regelmäß, um meine täglichen Feeds zu reduzieren. Allerdings überfliege ich die Titel oder durchsuche kurz fast alle Artikel in dieser Feed-Liste.

Anfangs habe ich meinen eigenen Miniflux-Service eingerichtet, um dies abzurufen, und einen RSS-to-Telegram-Bot verwendet, um Benachrichtigungen zu pushen. Kürzlich, nachdem ich begonnen hatte, Readwise Reader zu benutzen und die Erfahrung sehr gut fand, habe ich diesen Teil dorthin migriert. Ich verwende einen in Readwise Reader integrierten Verwaltungsmodus, der in drei Kategorien unterteilt ist:
- Später
- Shortlist
- Archiv
Ich scanne jeden Tag das Feeds-Panel und füge interessante Artikel zu “Später” als eine Lese-es-später-Liste hinzu. Natürlich werden aus Erfahrung Elemente in Lese-es-später-Listen oft zu “nie später gelesen”, wenn sie zu lange liegen bleiben. Daher bin ich beim Filtern sehr zurückhaltend und füge nur Artikel hinzu, die mich sehr interessieren und die ich sofort lesen werde, wenn ich Zeit habe, und ich verlange von mir selbst, die “Später”-Liste am Abend zu leeren.
Wir erhalten auch Informationen aus verschiedenen Ecken der sozialen Medien und des Internets, unter denen ich besonders an diesen Kategorien interessiert bin:
- Interessante Standpunkte/Tweet-Threads
- Interessante Artikel
- Nützliche Ressourcen
Wenn es sich um einige interessante Standpunkte oder Kommentare handelt, füge ich sie normalerweise nicht den entsprechenden Listen, Favoriten usw. der Software hinzu, sondern kopiere ihren Inhalt in Logseqs Journal und tagge sie entsprechend. Tatsächlich bieten viele Softwares (einschließlich Readwise Reader) Möglichkeiten, Tweet-Threads zu speichern oder andere bequeme Methoden, um Tweets zu speichern, aber ich bevorzuge es, sie selbst zu kopieren und zu organisieren, indem ich sie in wenigen Sätzen aufzeichne, anstatt nur einen Link zu speichern. Diese scheinbar absichtliche Erhöhung der Schritte ermöglicht es mir, diese Standpunkte noch einmal zu überprüfen, um zu vermeiden, von stark gelenkten oder emotionalen Standpunkten beeinflusst zu werden, und ist förderlicher für die Verdauung von Informationen und deren Internalisierung in meine eigenen Gedanken.
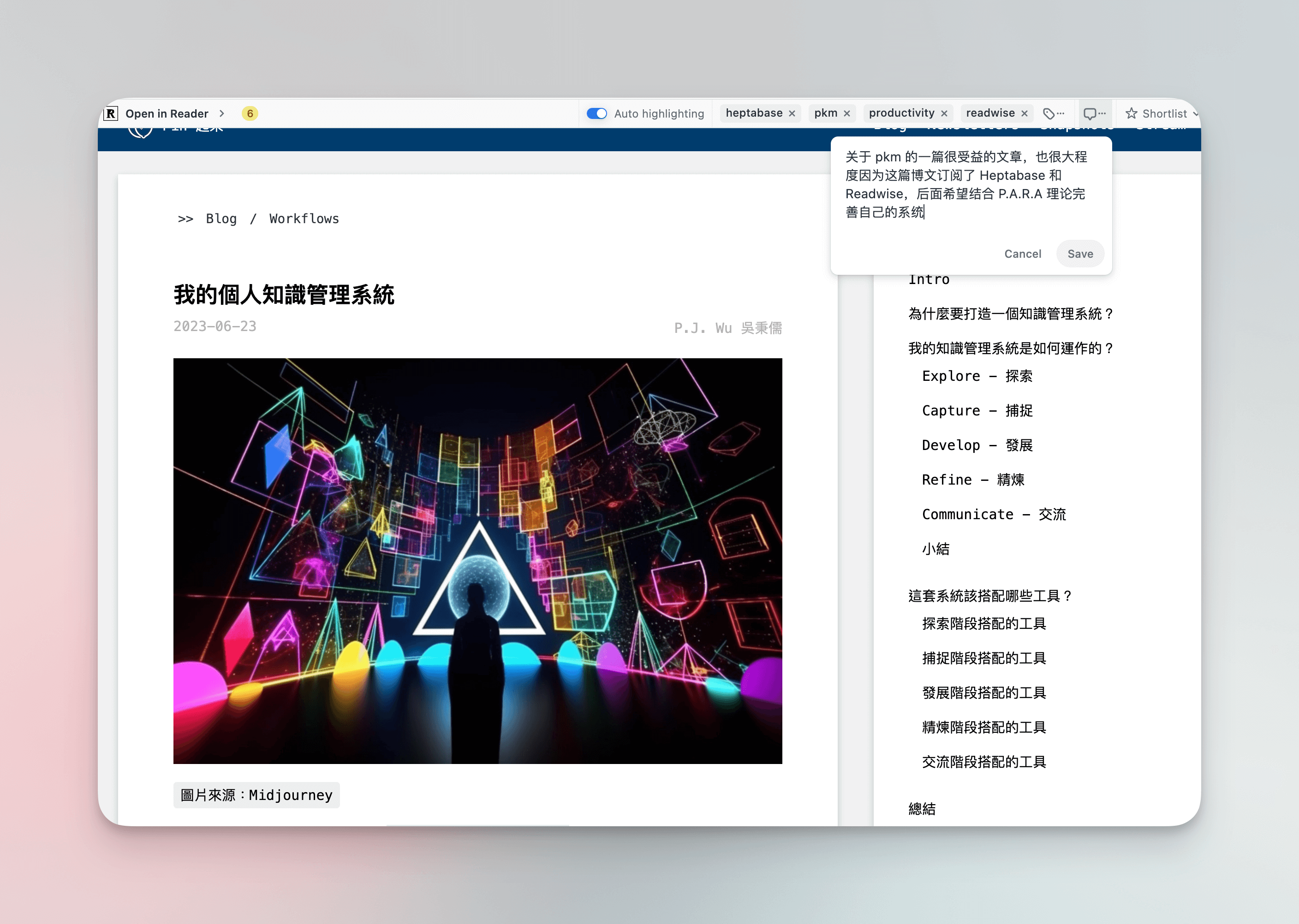
Wenn es sich um einige Artikel handelt, die mich interessieren, lese oder speichere ich sie mit Readwises Chrome-Erweiterung. Für diesen Teil verlange ich von mir selbst, jeden Artikel zu taggen und mit Notizen zu versehen, wobei die Notizen hauptsächlich beschreiben, warum ich diesen Artikel lesen möchte.
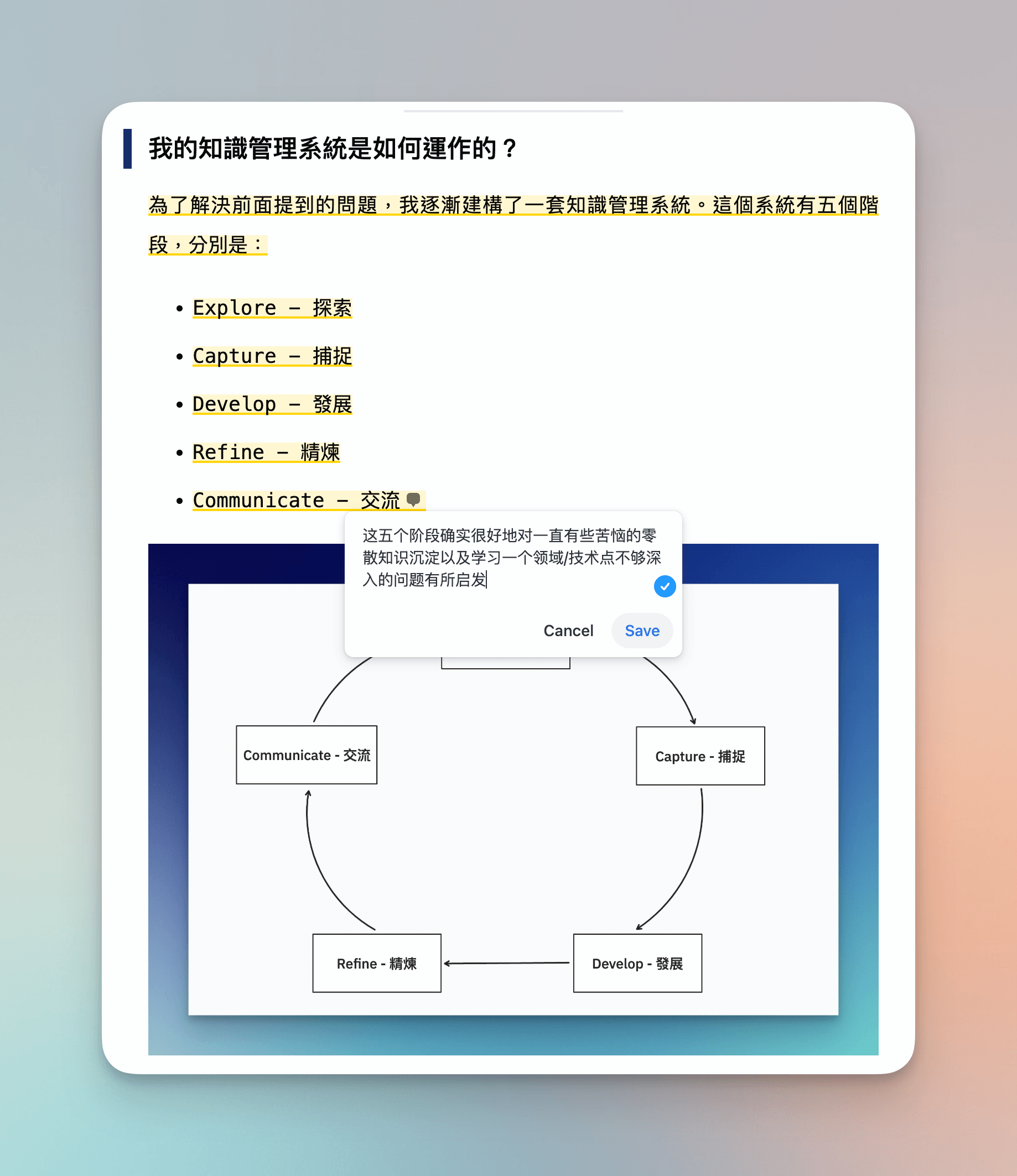
Darunter, wenn es sich nur um Artikel handelt, die überflogen werden müssen oder zur Informationssammlung dienen, füge ich sie der “Später”-Liste hinzu. Für tiefgehendes Lesen füge ich sie der Shortlist hinzu und muss einige bedeutungsvolle Teile hervorheben und versuche, meine eigenen Kommentare und Gedanken zu den Hervorhebungen hinzuzufügen. All dies kann direkt im Plugin erledigt werden, was sehr bequem ist.

Wenn es sich um nützliche Websites, Dokumente, Code, Software oder andere ressourcenähnliche Informationen handelt, verwende ich Pinboard, ein sehr altes, aber nützliches Lesezeichen-Management-Tool, um sie zu speichern. Ähnlich verwende ich eine Browser-Erweiterung, um sie zu speichern, und füge auch Tags und kurze Beschreibungen hinzu. In etwa einem Jahr habe ich 455 Lesezeichen angesammelt, von denen ich die meisten schnell durch Tags und Namen abrufen kann, wenn ich sie verwenden muss.
Für Video-Seiten und ähnliches verwende ich hauptsächlich Likes oder Favoriten, einerseits um die Ersteller zu unterstützen, und andererseits um sie durch einige Automatisierungstools mit meinem persönlichen Telegram-Kanal “Yu’s Life” zu synchronisieren und sie mit entsprechenden Tags zu versehen. Die meisten Videos sind jedoch nicht sehr informationseffizient, daher sind sie eher für interessante oder explorative Inhalte gedacht.
Fokussiertes Lesen
Abgesehen von diesen oben erwähnten passiv gepushten Informationsflüssen haben wir auch viele spezifische themen- oder feldspezifische Informationsbedürfnisse, die von uns verlangen, aktiv einige Bücher, Berichte usw. zu lesen.
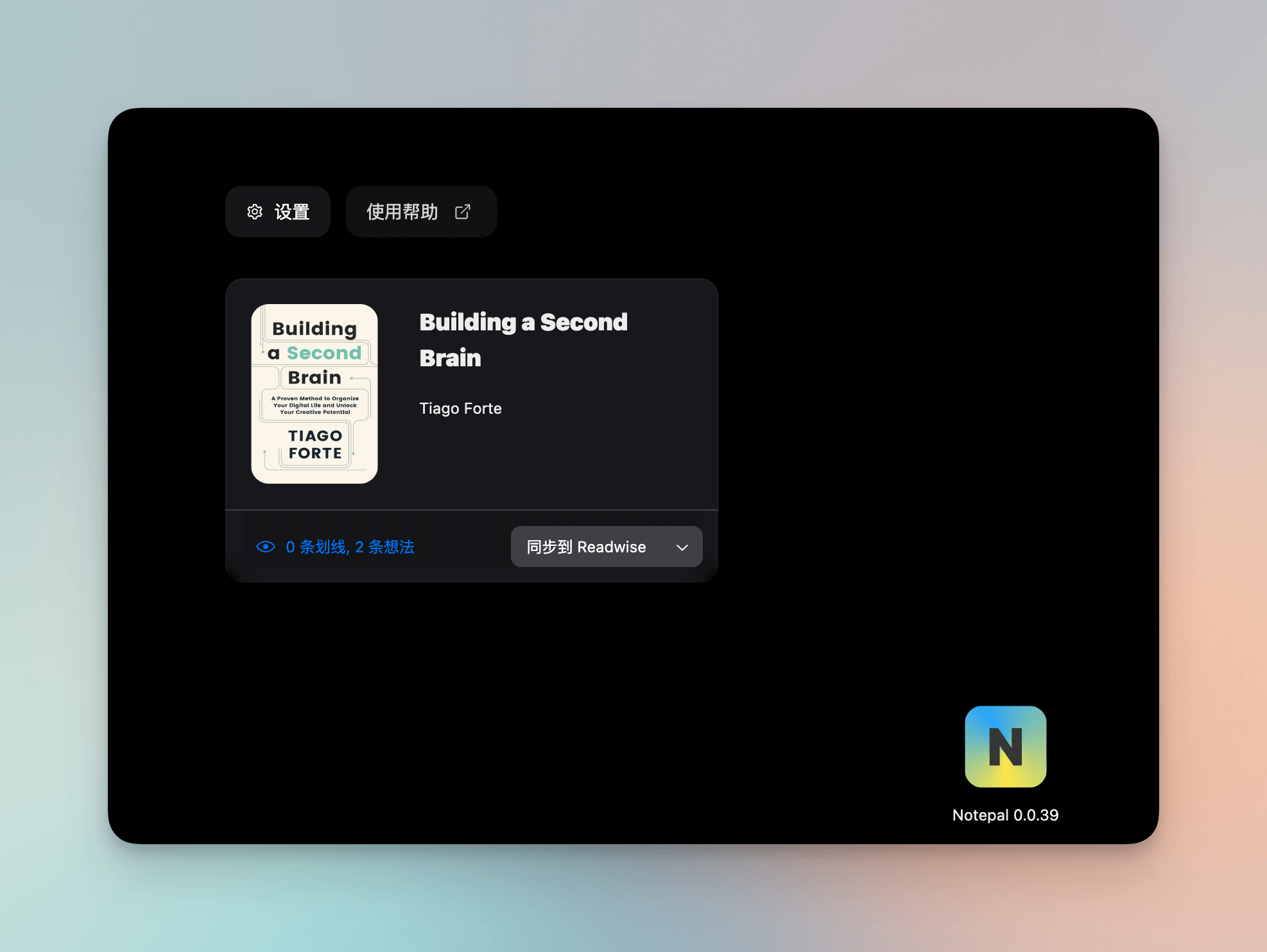
Für diesen Teil habe ich ursprünglich mehr Kindle verwendet oder physische Bücher gelesen und manuell einige Aufzeichnungen in Logseq gemacht. Aber nachdem Randy das Notepal-Tool gestartet hatte, begann ich, WeChat Reading zu verwenden. Es hat viele lesbare Buchressourcen, und ich benutze es auch, um Bücher im mobi- oder epub-Format zu importieren. Die Leseerfahrung ist recht gut.

Es ist auch sehr bequem, einige Notizen und Anmerkungen zu machen. Aufgrund der plattformübergreifenden Synchronisation ist es einfach, periodisch über die Notepal-Browser-Erweiterung mit Readwise zu synchronisieren, und der Effekt ist auch sehr gut (das obige Bild wurde synchronisiert). Dies bietet auch mehr Motivation, einige Bücher in fragmentierter Zeit zu lesen.
Informationsmanagement
Im vorherigen Abschnitt habe ich einige Kanäle und Systeme für die Informationsbeschaffung sortiert, aber dies sind immer noch verstreute Informationen. Um sie zu einem Teil unseres eigenen Wissens und Denkens zu machen, brauchen wir immer noch mehr Prozesse der Organisation, Verdauung und Ablagerung. Aber mit so vielen beteiligten Plattformen ist das Suchen und Organisieren nicht bequem, und es ist auch ziemlich schwierig, Verbindungen zwischen Informationen herzustellen. Inspiriert von dem Buch “Building a Second Brain”, das ich gerade lese, habe ich hauptsächlich die folgenden zwei Dinge getan:
- P.A.R.A als mein globales Tag-Klassifikationssystem geliehen und modifiziert
- Ein zweites Gehirn mit Logseq und Heptabase aufgebaut
Globales Tag-System

P.A.R.A ist ein vom Autor vorgeschlagenes Framework, das für Folgendes steht:
- Projects, bezogen auf laufende Projekte
- Areas, spezifische Domänen
- Resources, Ressourcen, die in Zukunft verwendet werden könnten
- Archives, abgeschlossene Projekte
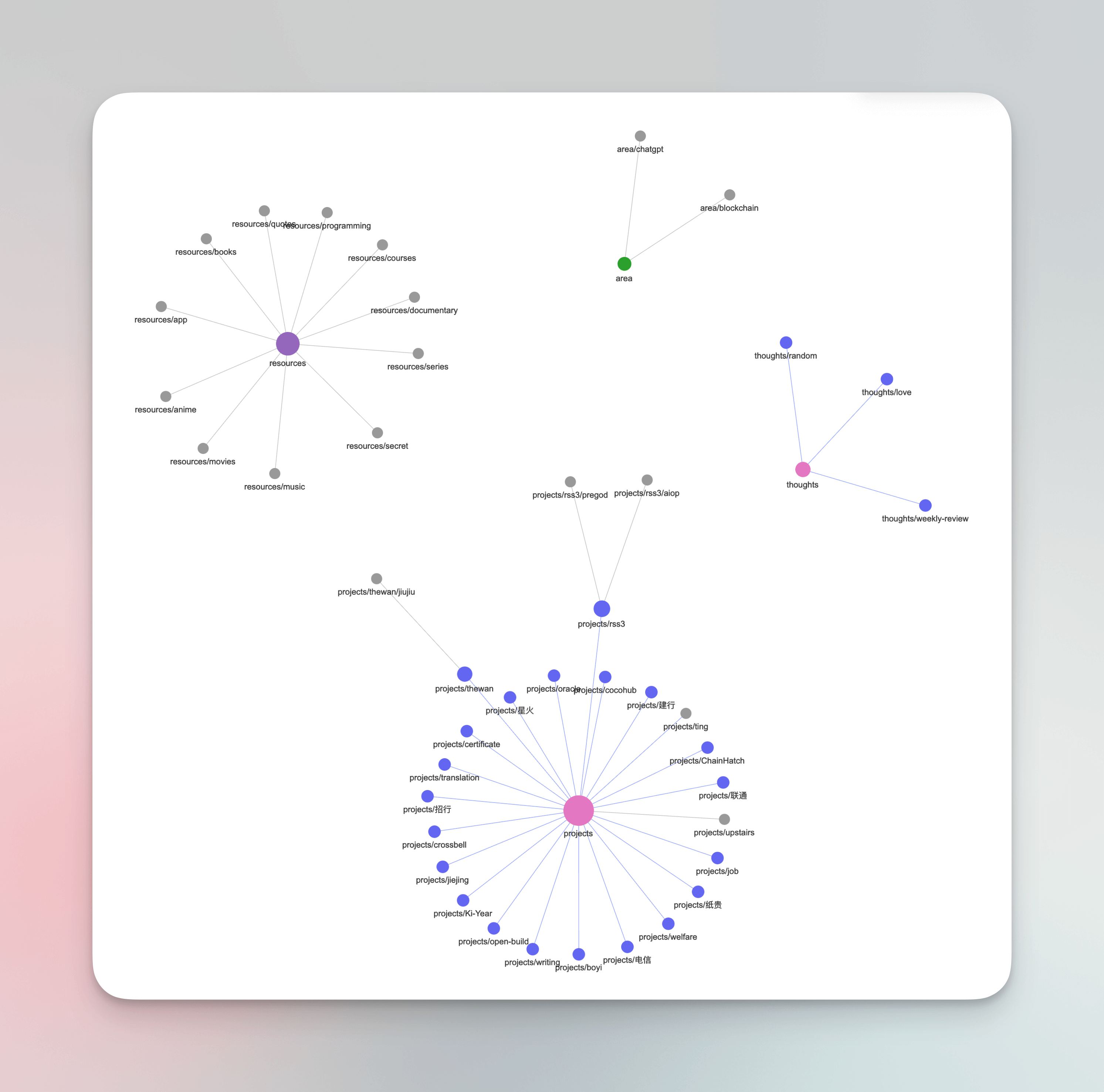
Basierend auf diesen vier Typen habe ich einen “Thoughts” hinzugefügt, um einige meiner zufälligen Ideen zu kategorisieren.
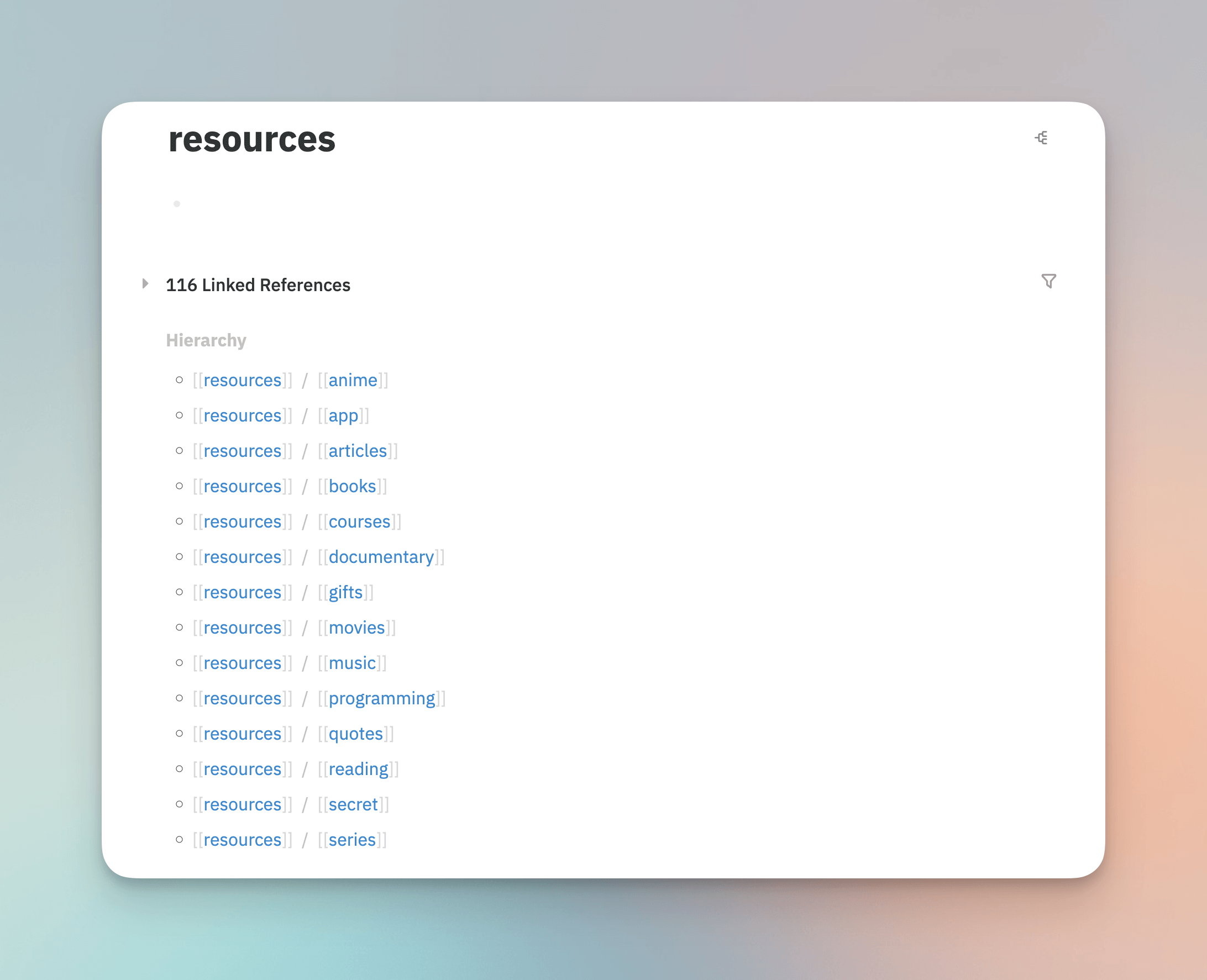
Meine Implementierungsidee ist es, diese fünf Typen als meine globalen First-Level-Tags zu verwenden, während spezifischere Projekte, Domänen, Branchen als Second-Level-, Third-Level-Tags verwendet werden können, wie Projects/writing/pkm, Areas/blockchain, Thoughts/weekly-review, usw. Logseq bietet ein sehr leistungsfähiges mehrschichtiges Tag-System, das automatisch nach / schichtet, was die Abfrage erleichtert und die Klassifizierung auf einen Blick klar macht. Nach der Modifizierung einiger meiner bestehenden Tags sieht das Ergebnis wie folgt aus:
Zweites Gehirn basierend auf Heptabase + Logseq
Ich habe Logseq schon immer als mein Wissensmanagement-System verwendet. Kürzlich sah ich, dass P.J. Wu Heptabase beigetreten ist, und erfuhr mehr über diese Plattform, also habe ich sie in mein Wissensmanagement-System integriert und nutze sie zusammen mit Logseq, um mein zweites Gehirn aufzubauen. Solange wir dem oben erwähnten Tag-System folgen, müssen die beiden Plattformen keine zusätzlichen Assoziationen haben, um Informationen unabhängig zu verwalten.

Dabei ist Logseq als Notiz-System, das einfaches Aufgabenmanagement und bidirektionale Links kombiniert, sehr gut geeignet, um diese Informationsflüsse und einige initiale Ideen, die nach meinem Lesen entstehen, wie Highlights und Kommentarnotizen, zu konsolidieren. Da Logseq ein offizielles Readwise-Plugin hat, ist es sehr bequem, meine Highlights und Notizen aus WeChat Reading und Online-Artikeln automatisch als Logseq-Seiten zu synchronisieren und sie über die Zeit mit dem Journal zu verknüpfen. Auf diese Weise kann ich intuitiv meine vergangenen Lektüren und Gedanken sehen, wenn ich täglich/wöchentlich einige Rezensionen schreibe. Zum Beispiel ist der obige Text einige Highlights und Notizen, die ich mit der Readwise Chrome-Erweiterung auf seiner Website gemacht habe, während ich Justin Yans Artikel “Jeder hat nur 24 Stunden am Tag, ich hoffe, meine Entscheidungen sind wirklich meine Entscheidungen” las, der automatisch mit Logseq synchronisiert und gemäß meiner Konfiguration mit einigen Tags und Eigenschaften versehen wurde.
Logseq eignet sich sehr gut für Informationsorganisation und Überprüfung, aber wenn ich ein bestimmtes Feld/Konzept recherchieren, den Kontext des Bücherlesens organisieren oder einen Blogbeitrag erstellen muss, scheint es etwas dünn zu sein. Seine Informationen sind in den täglichen Journalen in Blockeinheiten verstreut, assoziiert und durch bidirektionale Links oder Tags verknüpft, was für einige direkte visuelle Assoziationen nicht bequem ist und auch erfordert, dass man selbst in der frühen Phase klar genug über Schlüsselwörter und Tags ist, was immer noch eine gewisse kognitive Belastung darstellt. Für diesen Teil verwende ich daher Heptabase zur Verwaltung.
Heptabase kann als voll funktionsfähiges Whiteboard-Notiz-Tool betrachtet werden. P.J. Wu hat viele hochwertige einführende Artikel über Heptabase, die Sie lesen können, um mehr zu erfahren. Einfach ausgedrückt, ist es hauptsächlich in die folgenden drei Ebenen unterteilt:
- Map
- Whiteboard
- Card
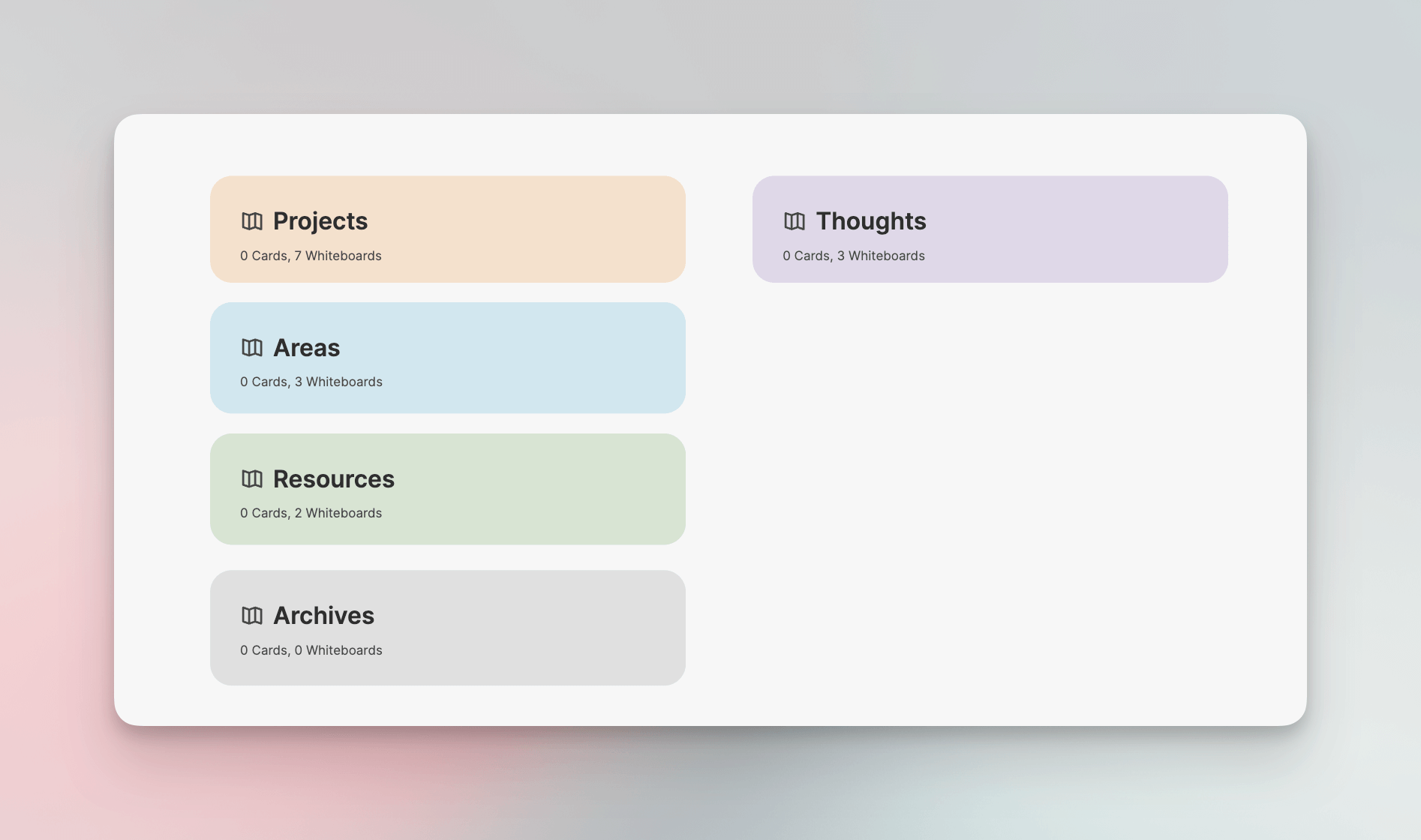
Dabei kann Map als der gesamte Raum unseres zweiten Gehirns betrachtet werden, der verschiedene Whiteboards enthalten kann. Ich habe fünf Whiteboards als First-Level-Tags erstellt.
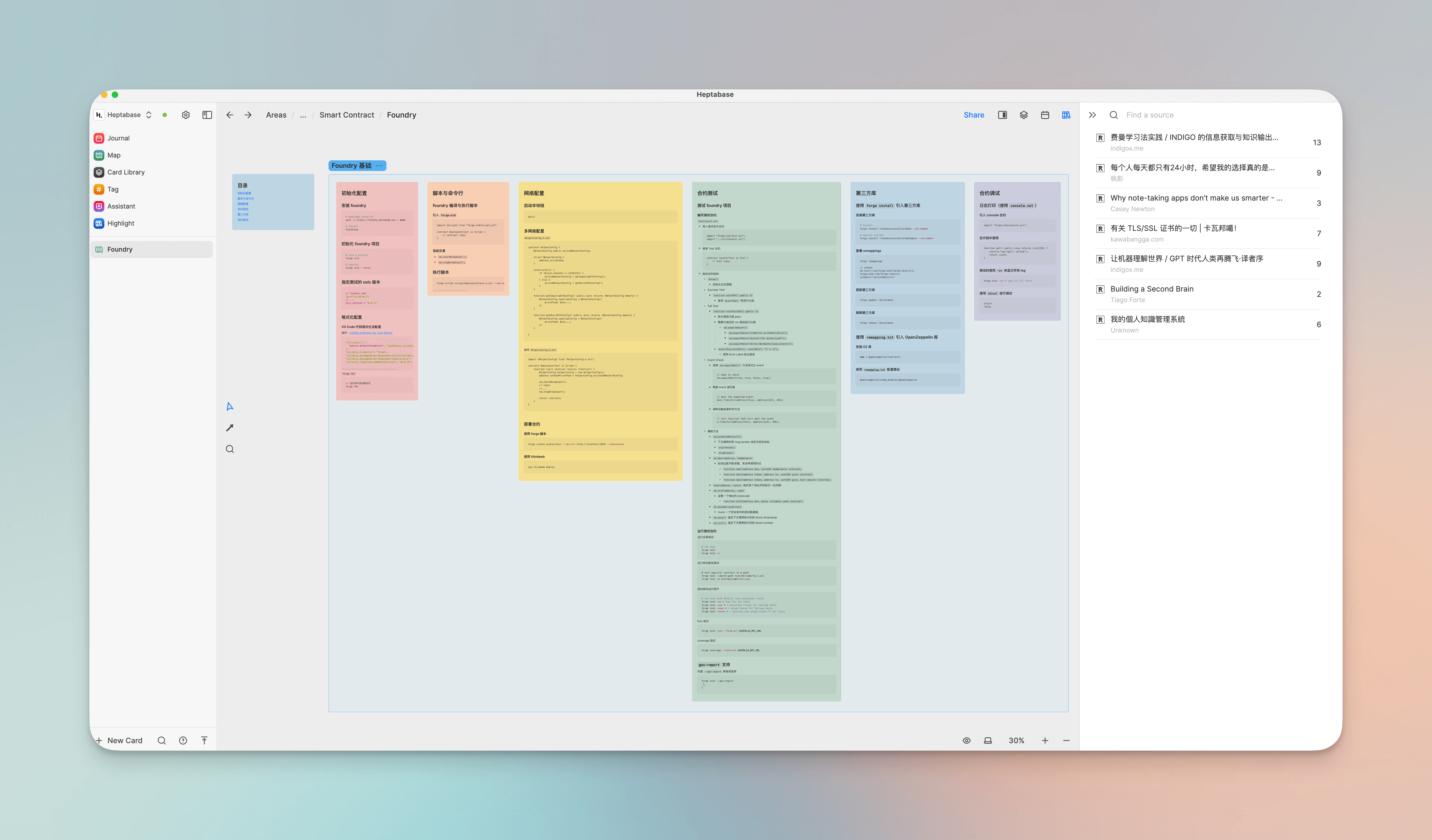
Karten repräsentieren einzelne Ideen oder unabhängige Informationspunkte in unserem Gehirn. Wir können unser Wissen durch die Assoziation zwischen Karten und die Hierarchie zwischen Whiteboards und Karten organisieren.
Als ich das Tutorial für das Foundry Smart Contract Entwicklungs-Framework schrieb, legte ich zunächst einige verstreute Wissenspunkte oder Erfahrungen und Lektionen, die in der Praxis auftraten, als einzelne Whiteboards auf dem Foundry-Whiteboard aus (das ist das vierte Unterlevel-Whiteboard unter Projects - Blockchain - Smart Contract). Wenn ein bestimmter Wissenspunkt ausreichend war, würde ich einige Abschnittsgruppierungen und Linienverbindungen zwischen Whiteboards vornehmen.
Es bietet auch eine native Integration mit Readwise, die es uns ermöglicht, direkt einige Highlights und Notizen aus bestimmten Artikeln oder Büchern in Readwise als Karten auszuwählen und sie in der rechten Seitenleiste in das Whiteboard einzuführen und einige Assoziationen für sie herzustellen. Es ist dem Prozess unseres Gehirns, verstreute Informationen zu organisieren oder Brainstorming zu betreiben, sehr ähnlich und erfüllt perfekt meine Bedürfnisse.
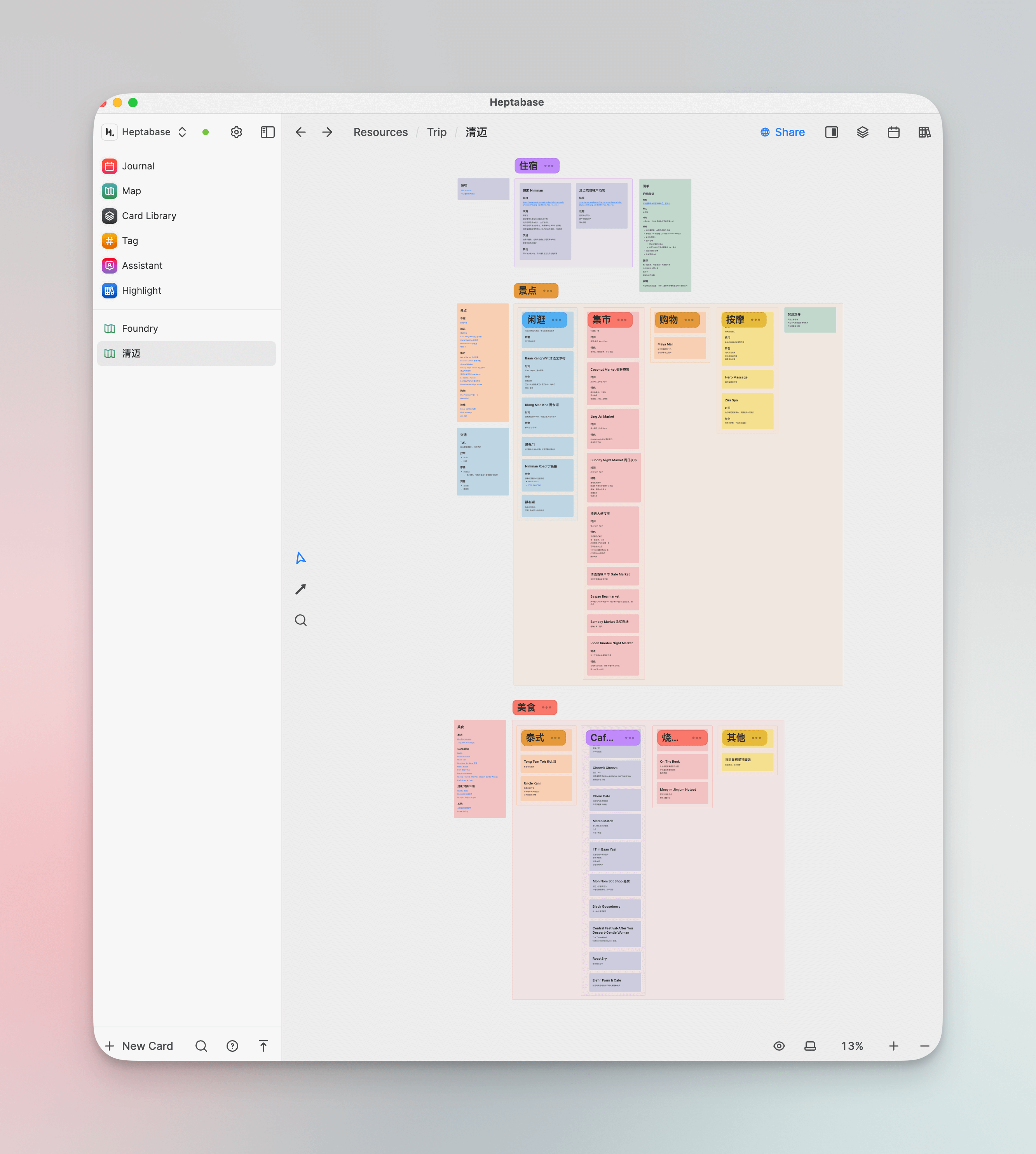
Ich verwende es derzeit auch, um einige Reiseführer zu erstellen, indem ich Informationspunkte aus Xiaohongshu und anderen Strategiebeiträgen von Leuten als einzelne Karten auf das Reiseplanungs-Whiteboard lege und sie dann durch Assoziationen und Gruppierungen organisiere, was sehr ordentlich ist.
Informationsoutput
Mein Output umfasst hauptsächlich die folgenden Teile:
- Notizen/Standpunkte/Tägliches Leben
- Lange Artikel
- Thematische Forschung
- Informationsfluss
Notizen/Standpunkte/Tägliches Leben
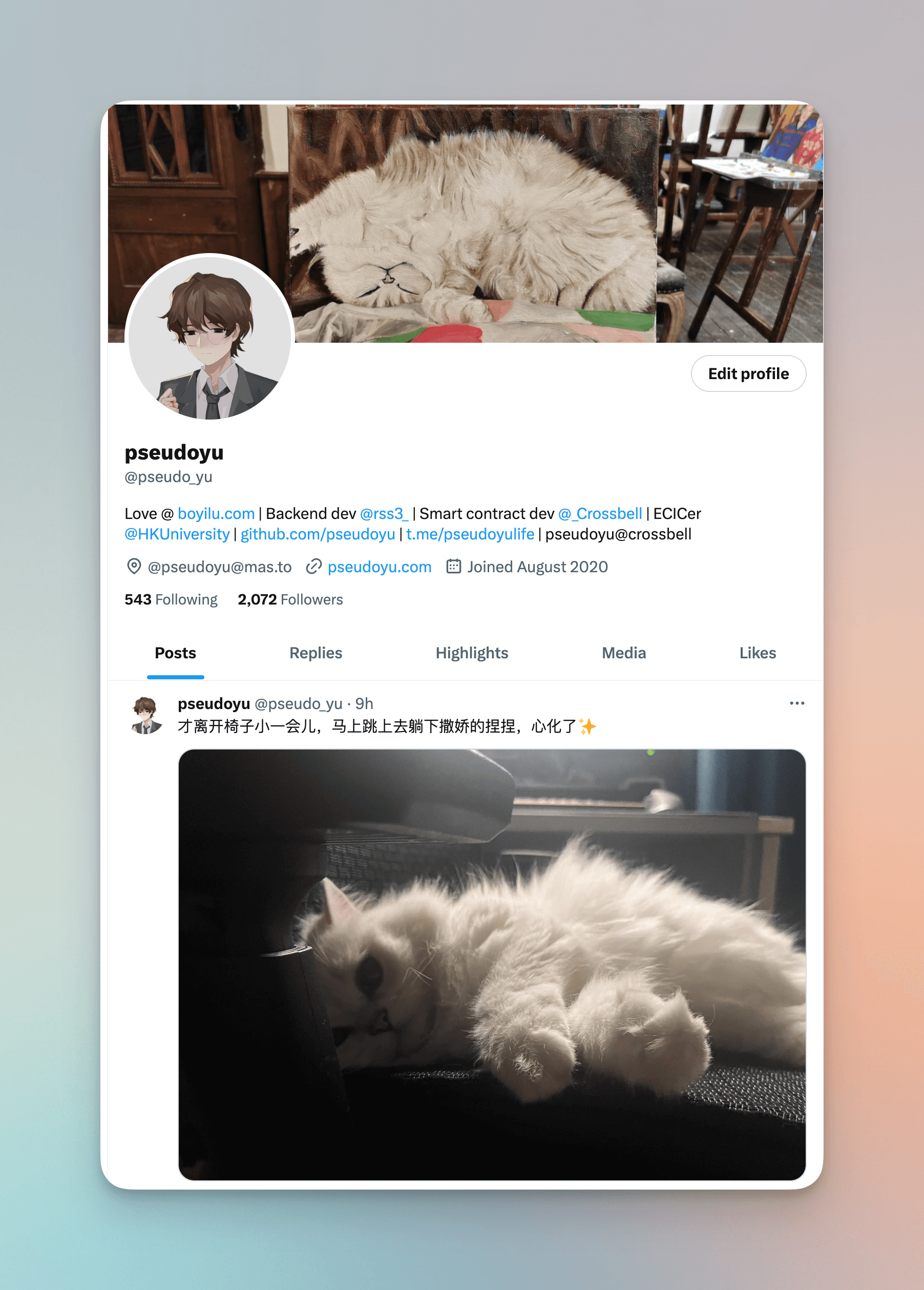
Darunter ist Twitter “pseudo_yu” mein Hauptkanal für unstrukturierten Informationsoutput. Manchmal sind es einige Ideen über neue Technologie, Gefühle über die Arbeit, Emotionen über das Treffen von Freunden oder ein süßes Katzenbild, all das macht meinen Output aus und entspricht auch der schnellen Produktion jener zufälligen Gedanken in meinem Input.
Die Freunde, die ich auf Twitter getroffen habe, haben mir auch viel Wärme gebracht.
Lange Artikel
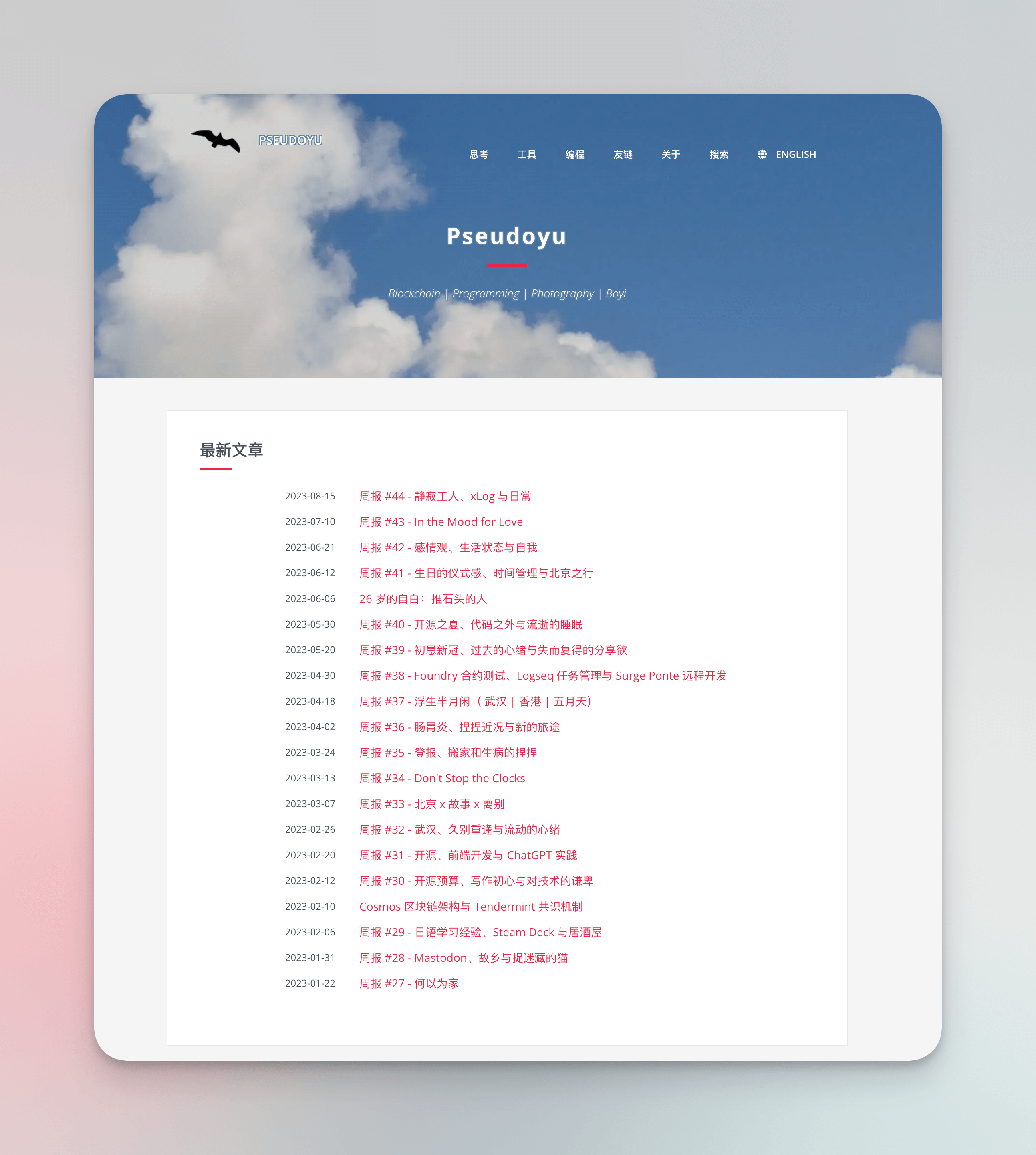
Meine wichtigste Output-Plattform ist mein persönlicher Blog “Pseudoyu”. Derzeit ist der Wochenbericht mein Hauptauslass, und gelegentlich gibt es auch einige thematische oder spezielle Blogbeiträge über Technologie oder Produktivitätstools.
Thematische Forschung
Das Erstellen eines Blogbeitrags hat aufgrund von Überlegungen zu Zielgruppe, Wortwahl, Ausdruck und Vollständigkeit tatsächlich eine gewisse kognitive Belastung und einen längeren Zyklus. Im Prozess der Durchführung thematischer Forschung in spezifischen Bereichen lege ich Lernmaterialien und einige Demos meist in GitHub-Repositories oder in irgendeiner Ecke von Logseq-Notizen ab. Manchmal muss ich sie nach langer Zeit neu erlernen. Jetzt lege ich sie mehr auf einem Whiteboard in Heptabase ab, das viele kleine Wissenspunkte speichern und in nachfolgenden Kreationen weiter zusammenfassen und verfeinern kann. So kann ich dieses Whiteboard tatsächlich teilen, nachdem es einen grundlegenden Rahmen hat, was mehr Kommunikation mit anderen ermöglicht und auch Freunden hilfreich sein kann, die das Gleiche lernen.
Informationsfluss-Output
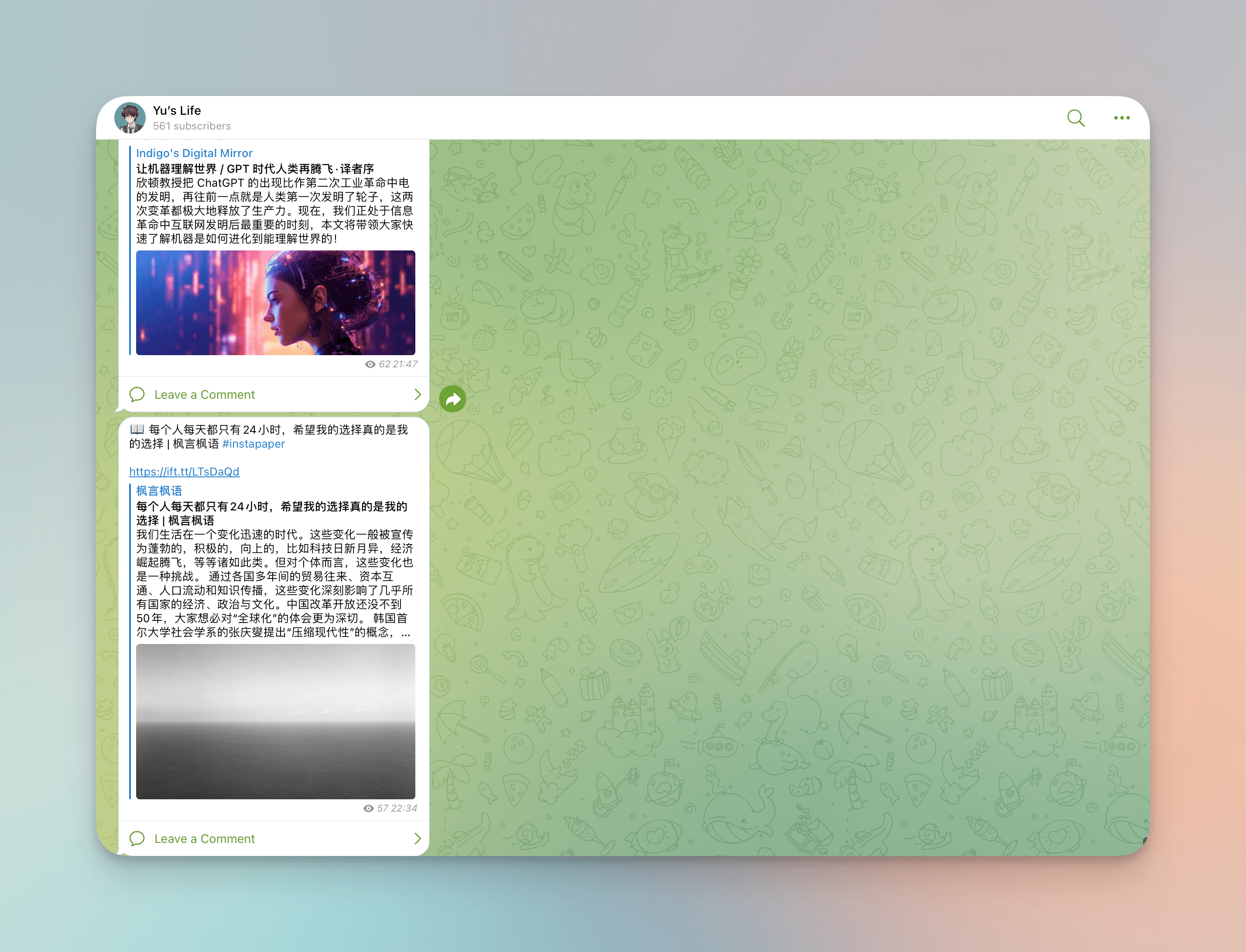
Ich habe meinen eigenen n8n-Synchronisationsdienst eingerichtet, um meine verstreuten Informationseingaben und -ausgaben auf verschiedenen Plattformen zu sammeln, und ich poste auch meine Gedanken zu Filmen, Büchern und andere Gedanken in meinem Telegram-Kanal “Yu’s Life”. Ich folge auch einigen Kanälen und Gruppen, um einige Informationen zu erhalten oder Gleichgesinnte zu treffen, und leite gelegentlich manuell weiter. Die Hauptplattformen, die ich synchronisiere, sind:
- Blog, der jetzt mehr wie ein Lebensprotokoll aussieht.
- YouTube, ich bin auch ein starker Nutzer, sehe mir viele technische Tutorials und digitale Informationen an, und gelegentlich gibt es viel interessanten Inhalt.
- Bilibili, hauptsächlich einige Blogger beibehaltend, denen ich seit vielen Jahren folge, mehr Reise-Vlogs anschauend, nur Dynamiken und nicht die Homepage oder heiße Themen betrachtend.
- Pinboard, ein Lesezeichen- und Website-Speicher-Management-Tool, auf das ich stark angewiesen bin.
- Instapaper, Verwaltung von Lese-es-später-Elementen, hauptsächlich einige hochwertige oder lange Artikel speichernd.
- GitHub, auch täglich durchstöbernd, einige gute Projekte anschauend und Stars mit Listen verwaltend.
- Spotify, gute Lieder markierend.
- Douban, meine Bücher, TV-Serien, Filme, Anime und Spiele aufzeichnend. Ich bin auch ein starker Nutzer und versuche, meine eigene Rezension für jedes Werk zu schreiben, das ich gesehen/gespielt habe.
Datensicherung
Obwohl Plattformen wie Twitter und Telegram bereits ziemlich groß sind, sind sie immer noch zentralisierte Produkte. Zudem bin ich angesichts der jüngsten Turbulenzen immer unruhig, wenn ich Telegram als Endstation für die Aggregation dieser Informationsquellen verwende, besonders da ich oft fast versehentlich auf das Löschen aller Nachrichten klicke, wenn ich Nachrichten lösche (seltsame Interaktionserfahrung). Daher ist die Synchronisation und der Export von Informationen auch ein sehr wichtiger Teil. Ich verwende die xLog- und xSync-Dienste unter dem Crossbell-Ökosystem für die On-Chain-Sicherung meines Blogs und Informationen von verschiedenen Plattformen.
xLog
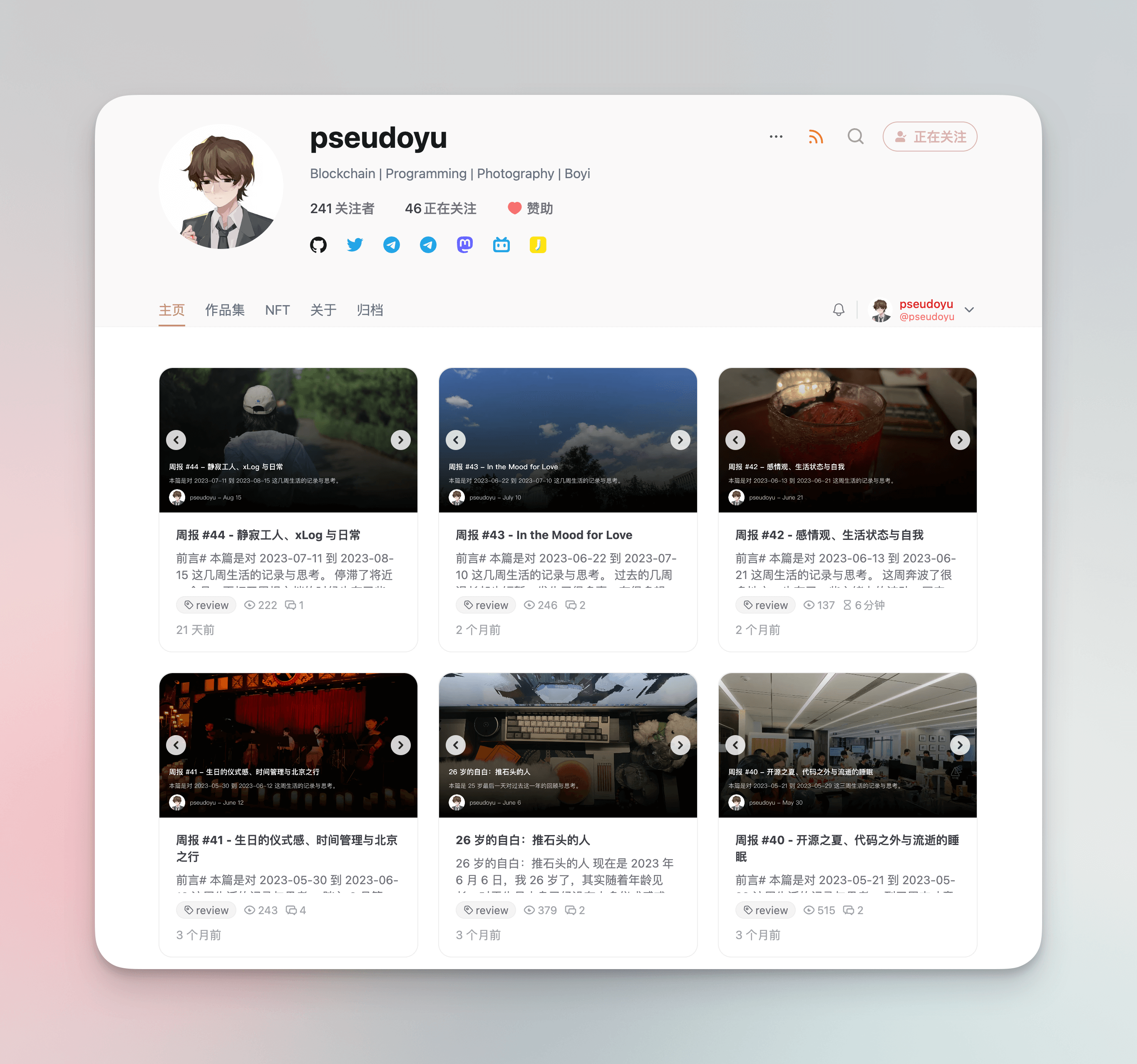
Der visuelle Effekt und die Erfahrung sind ziemlich gut, und es ist einfach, basierend auf der Crossbell-Adresse zu folgen und zu kommentieren. Es beinhaltet Funktionen wie NFT-Showcase und persönliches Portfolio. Dies ist meine xLog-Zugangsadresse, interessierte Freunde können auch folgen. Allerdings ist es derzeit, in Anbetracht des Grades der Anpassung, verschiedener historischer Artikel-Migrationsrouting-Probleme, Änderungen in meinen eigenen Datenstatistikdiensten usw., immer noch mehr ein Synchronisations-Verteilungskanal.
xSync
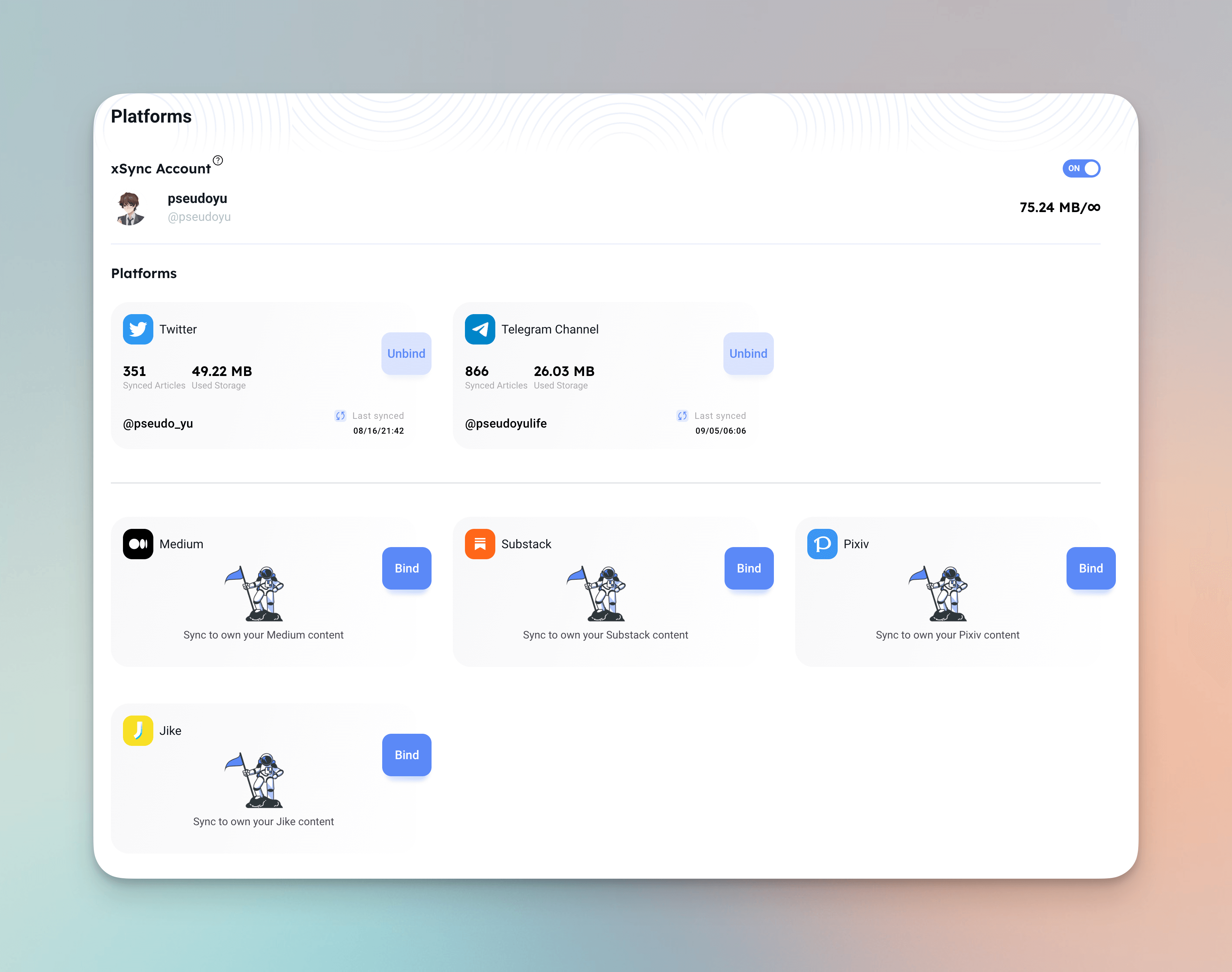
xSync kann Plattformen wie Twitter, Telegram Channel usw. synchronisieren. Ohne invasive Modifikationen kann es eine zweite Sicherung und Archivierung meines aggregierten Kanals erstellen. In Zukunft kann ich meine verschiedenen Nachrichten durch xChar betrachten, was eine perfekte Lösung ist. Dies ist meine xChar persönliche Homepage: xChar, und Sie können auch meinen Informationsfluss durch xFeed betrachten.
Schlussfolgerung
Es ist wahrscheinlich ein Fehler, am Ende Software zu bitten, unser Denken zu verbessern.
Casey Newton sagte dies in einem kürzlichen Artikel “Warum Notiz-Apps uns nicht schlauer machen”. In der Tat können diese Systeme oder Softwaretools letztendlich nur unser Informationsmanagement und den Output unterstützen und können unser Denken nicht ersetzen. Der Aufbau eines Wissensmanagement-Systems kann jedoch, während wir uns selbst erfreuen, das Denken auch effizienter machen. Sich selbst zu erfreuen ist der Weg, andere zu erreichen und dadurch wertvolleren Output zu produzieren.
Ich hoffe, dieser Artikel kann für alle hilfreich sein.
Verwandte Beiträge
