前言
最近在做学校的 Case Study 项目,是一个基于Ethereum平台的音乐版权管理项目,其中对于音乐作品、版权证明文件等上传用到了 IPFS 分布式文件存储技术,主要是利用其去重的特性来检测侵权行为。对 IPFS 这个系统产生了兴趣,阅读了QTech 平台上的IPFS 系列文章,也查询了一些相关资料,通过本文梳理一下,如有错漏,欢迎交流指正。
概述
我们日常使用网盘或其他服务时大多都是访问文件所在的特定的服务器(IP 地址),请求文件并下载到本地,通过的是 HTTP 协议,本质上是基于位置寻址的,访问 URL 来得到一层层找到具体的文件,这种方式固然便捷,但是存在一些问题。文件依托于特定的服务器,因此一旦中心化的服务器宕机或者文件被删除了,内容将永久丢失,并且如果离服务器很远/同时访问文件的人很多的话访问速度也会比较慢;而且同样一份文件可能重复存储在不同的服务器中,造成资源的浪费;此外就是存在严重的安全隐患,DDoS、XSS、CSRF 等攻击都可能对文件安全性造成威胁。
那有没有更好的解决方案呢?
试想我们把文件存储在一个分布式网络里,每个节点都可以存储文件,用户可以通过访问一个类似目录索引的方式来向最近的节点互相请求文件。这就是 IPFS 星际文件系统的解决思路,它是一个点对点的超媒体文件存储、索引、交换协议,由 Juan Benet 在 2014 年 5 月发起。
特点
IPFS 想把全世界所有部署了相同文件系统的计算设备链接在一起,构建一个分布式网络来替代传统中心化的服务器模式,每个节点都可以存储文件,用户通过DHT(Distributed Hash Table)分布式哈希表来获取文件,速度更快、更安全,网络安全性更强。
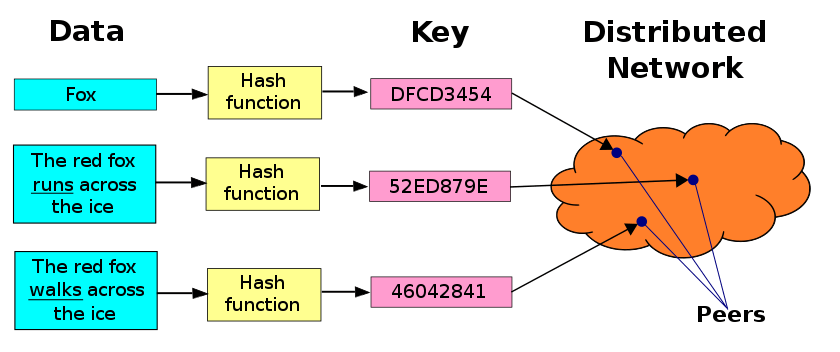
因为通过 IPFS 存储的文件内容是通过分块求 Hash 值存储为地址的,本质上是通过多重哈希来确定文件的地址,这是一种去中心化但是基于内容寻址的方式,通过对数据本身进行加密,生成独一无二的 Hash 以供查找,这种方式下,即使是微小的改变,也会造成 Hash 结果截然不同,因此很容易能够从 Hash 检测内容是否被篡改,甚至不用访问文件本身。
不同于传统的服务器模式,IPFS 是一个统一的网络,因此已经上传的相同内容的文件不会重复存储(可以通过 Hash 值检验),极大地节约了整体网络资源,也更加高效。而且理论上只要节点达到一定规模,文件将永久保存,且同一个文件可以从多个(也更近)的节点下载,通讯效率也会更高。
除此之外,因为是分布式网络进行存储,也可以天然地避免传统 DDoS 等攻击。
功能
除了文件存储外,IPFS 还有 DHT 组网、Bitswap 文件交换等功能,之后也会单独写博文进行讲解。
工作原理
作为一个文件存储系统,上传文件和下载文件是两个最基本的操作,我们分别讲一下原理。
IPFS add 命令
在 IPFS 系统中执行 add 操作就完成了上传操作,那是怎么上传的呢?
在 IPFS 文件存储系统中,每当上传一个新文件,系统会将单个文件拆分成若干个 256KB 的 block,每个 block 会有一个专属的 CID 进行标识,这个后面会详细讲;然后计算每一个 block 的 Hash 值,并存储再一个数组中,最后对这个数组求 Hash 得到文件的最终 Hash 值;接着将文件的 Hash 和所有的 blocks Hash 的数组组成成一个对象,也就形成了一种索引结构;最后把文件 block 和这个索引结构全部上传到 IPFS 节点,同步到 IPFS 网络。
文件上传时有两个值得注意的情况:1.文件特别小,如果文件小于 1KB 的话就不浪费一个 block 了,会直接和 Hash 一起上传到 IPFS。2.文件特别大,比如之前上传了一个 1G 的视频,之后又加了几 KB 的字幕文件,这种情况下未变化的 1G 部分是不会重新分配新的空间的,而只会为追加的字母文件部分分配新的 block,再重新上传 Hash。
因此,很好理解的是,即使是不同文件的相同部分也只会存储一份,很多文件的索引会指向同一个 block,所形成的结构就是 MerkleDAG 数据结构。
值得注意的是,当节点执行 add 操作时,会保留到本地 blockstore 中,但不会立刻主动上传到 IPFS 网络中,也就是说,与其连接的节点并不会存储这个文件,除非有某个节点请求过该 block 数据!因此,它并不是一个自动备份数据的分布式数据库。IPFS 这种设计是出于网络带宽、可靠性等方面的考虑。
还有一个细节就是,当节点在执行add命令时,还会广播自己的块信息,并维护一个所有发给这个节点的 block 请求列表,一旦 add 命令添加到数据满足这个列表,就会主动向对应的节点发送数据并且更新列表。
IPFS get 命令
那文件上传后,要怎么查找访问呢?
这就关系到上文所提到的 IPFS 索引结构是DHT(分布式哈希表),通过对DHT进行访问可以很快访问得到数据。
那如果想要查找一个本地没有的数据呢?

在 IPFS 系统中,所有和当前节点连接的节点会构成一个 swarm 网络,当节点发送一个文件请求(即get)时,首先会在本地的 blockstore 里查找请求的数据,如果没找到的话,就会向 swarm 网络发出一个请求,通过网络中的DHT Routing找到拥有该数据的节点。
怎么知道网络中哪个(哪些)节点拥有这个请求文件呢?
如上文add命令所讲的那样,当一个节点加入到 IPFS 网络中后,会告诉其它节点自己存储了什么内容(通过广播DHT),这样每当有用户希望检索的内容正好在这个节点上时,其它节点就会告诉用户要从这个节点索取他想要的内容。
一旦找到拥有这个数据的节点,就会把请求数据反馈回来,这样本地节点会把收到的 block 数据缓存一份到本地的 blockstore 中,这样整个网络中相当于多了一份原数据的拷贝,更多节点请求数据的话,查找就变得更容易,因此数据的不可丢失性也是基于这个原理,只要有一个节点保存着这个数据,就可以被全网获取。
在项目中,上传的文件可以通过
ipfs.io网关直接获取到文件,类似于https://ipfs.io/ipfs/Qm.....这样的网站地址,这个是什么原理呢?

ipfs.io网关实际上就是一个 IPFS 节点,当我们打开上述这个网络链接的时候,实际上就是向这个节点发送了一次请求,因此ipfs.io网关会帮我们去向拥有这个数据的节点请求这个 block(如果这个文件是自己刚在本地节点通过add命令添加的话就会通过这种方式被上传到 IPFS 网络上),在swarm网络中通过DHT Routing获取到数据后,网关会自己先缓存一份,然后将数据通过 HTTP 协议发给我们,因此,就可以在浏览器直接看到这个文件啦!
而任何其他机器通过浏览器访问这个链接时,因为ipfs.io网关已经缓存了这个文件,再次请求的时候,就不需要向原节点来请求数据了,可以直接从缓存中返回数据给浏览器。
内容标识符 CID(Content-ID)
现在考虑另一个问题,我们常见的图像为.jpg、.png,而常见的视频则是.mp4一样,可以直接从后缀名判断文件类型。通过 IPFS 上传的文件也可以是多种类型,也包含了很多信息,怎么进行分辨呢?
IPFS 早期主要使用base58btc对multihash进行编码,但是在开发 IPLD(主要用来定义数据,给数据建模)的过程中会遇到很多与格式相关的问题,因此使用了一种叫CID的文件寻址格式来对不同格式的数据进行管理,官方的定义为:
CID是一种自描述式的内容寻址的识别符,必须使用加密散列函数来得到内容的地址
简单来说,CID通过一些机制来对文件所包含的内容进行自描述,包含了版本信息、格式等。
CID 结构
目前CID有v0和v1两种版本,v1版本的CID由V1Builder生成
<cidv1> ::= <mb><version><mcp><mh>
# or, expanded:
<cidv1> ::= <multibase-prefix><cid-version><multicodec-packed-content-type><multihash-content-address>如上面列举的代码所示,采用的机制叫multipleformats,主要包括:multibase-prefix表示CID编码成字符串,cid-version表示版本变量,multicodec-packed-content-type表示内容的类型和格式(类似于后缀,但是作为标识符的一部分,支持的格式有限,且用户是不能随意修改的),multihash-content-address表示哈希值(让CID可以使用不同的 Hash 函数)。
目前CID支持的multicodec-packed编码有原生的protobuf格式、IPLD CBOR格式、git、比特币和以太坊对象等格式,也在逐步开发支持更多格式。
CID代码详解:
type Cid struct {str string}
type V0Builder struct {}
type V1Builder struct {}
Codec uint64
MhType uint64
MhLength int // Default: -1Codec表示内容的编码类型,如DagProtobuf, DagCBOR等,MhType表示哈希算法,如SHA2_256, SHA2_512, SHA3_256, SHA3_512等,而MhLength则表示生成哈希的长度。
而v0版本的CID由V0Builder生成,以Qm字符串开头,向后兼容,multibase一直为base58btc,multicodec一直为protobuf-mdag,cid-version一直为cidv0,multihash表示为cidv0 ::= <multihash-content-address>。
设计理念
通过CID这种二进制的特性,大大提高了对于文件 Hash 的压缩效率,因此可以直接作为 URL 的一部分进行访问;通过multibase的编码形式(如base58btc)缩短了CID的长度,这样更容易传输;可以表示任意格式、任何哈希函数的结果,十分灵活;可以通过结构中cid-version参数进行编码版本的升级;不受限于历史内容。
IPNS
如上文所述,IPFS 中文件内容的改变会造成其哈希值的变化,在实际应用中,如果通过 IPFS 托管网站等需要版本更新迭代的应用,每一次都通过更新后的 Hash 访问很不方便,因此,需要一个映射方案以保证用户体验,这样用户在访问时仅需要访问一个固定地址。
IPNS(Inter-Planetary Naming System)就提供了这样的服务,它提供了一个被私钥限定的哈希 ID(通常是 PeerID)来指向具体的 IPFS 文件,文件更新后会自动更新哈希 ID 的指向。
即使哈希值可以固定不变了,但是依然不便于记忆和输入,因此,有了更进一步的解决方案。
IPNS 同样兼容 DNS,可以使用DNS TXT记录域名对应的 IPNS 哈希 ID,就可以域名来替换 IPNS 哈希 ID 来进行访问,从而实现更容易读写和记忆。
总结
以上就是对 IPFS 分布式存储原理的梳理,它的组件、存储流程细节、GC 机制、数据交换模块 Bitswap、网络以及实际应用场景都有很多值得深入挖掘的部分。
推荐阅读:趣链科技 QTech 平台《IPFS 系列文章》
参考资料
- IPFS 官网
- 原来 IPFS 是这样存储文件的,QTech,趣链科技
- IPFS 到底怎么工作的?,知辉
- 站在 Web3.0 理解 IPFS 是什么,Tiny 熊,登链社区
- IPFS CID 研究,Sophie Huang