前言
我似乎一直有一种把自己作为一个机器来看待的倾向,常常会以置身事外的视角来观察自己,集成各个模组,并不断折腾和优化。当自己搭建的某种行为模式或是习惯在某个时刻突然发挥了作用就会有一种欣喜感,而当受到外界或是自身状态影响而停止运转时则会有一种秩序感被打破的重度不适。
作为一个效率工具控,我的个人知识管理与信息管理则可以说是自己最重要的一部分。其实本没有想要写这篇文章,有太多的先例实践在前,而自己也只是一种前人基础上的微调优化,常常没有什么信心去分享,而这周重新搭建和优化了一下自己的知识管理系统,很开心,有一种想要记录下来的冲动,本来只是想在周报里稍稍提及,却发现越写越收不住,于是就有了这篇文章。
其实之前对于信息输出在周报中时常有提及,所以本文也会覆盖一些之前的内容,并且终于补上了信息获取和知识管理的部分,就作为一个总集篇了。其中,理论的部分,如“费曼学习法”、“卢曼卡片盒笔记法”已经有很多很好的介绍文章,不再花篇幅介绍了,而更多的是阐述我使用的软件工具实践,希望能够对大家有所帮助。
信息获取与管理
不知道从什么时候起,其实能很明显感受到自己对网络世界信息的依赖。可能有别于游戏瘾或是经常被诟病的短视频算法鸦片,我的这种依赖并不是机械性地刷刷刷,或是面对焦虑时的逃避,而是一种对于信息获取的渴求,甚至内化为了一种生活方式。因为我对自己的信息筛选和消化能力颇有信心,所以其实一直以来没有在输入源和整理上花太多的心思。
而随着自己接触和感兴趣的领域越来越多,信息不断积累,有时候仅仅是浏览和通读都已经有些超过了记忆负荷,并且这些信息常常也零散地留在我的笔记或是脑海的某个角落中,并没有成为内化的一部分,以后也很难记起或是检索,于是重新对自己的信息获取方式进行了梳理。
信息源分类
我的信息来源按照大类可以分为以下几类:
- 随机想法
- 信息流
- 聚焦阅读
随机想法

在日常生活、工作、学习或是什么任意的时刻,我有时候会萌生一些随机的想法,这些想法和当前所做的事并不相关或是天马行空,但也许会在未来的某个时刻被用到。因为我大部分时间都不会离开电脑太远,我通常会记录 Logseq 的 Journal 中,有时可能会临时发在一个只有自己一个人的微信群中或是 Telegram 的 Saved Message 中,后续再补充上去。
信息流
我每天从起床开始就会被来自各个平台的信息流所裹挟,依赖于网络世界其实最难免的是与社交媒体与算法的抗争,一方面是要避免自己被过载的贩卖焦虑的信息或是熟人社交圈的“Peer Pressure”所困扰,另一方面也需要警惕算法所构造的信息茧房。实话说这一点挺难做到,即使自己多少算是具备一些克制和过滤信息的能力并有意识在这样做,但依然难以避免被其所扰乱思绪或是引导。
我最后采取了一种简单却也行之有效的方式 —— 关闭微信朋友圈入口与大部分软件通知提醒,并且把大部分不带社交属性而仅仅是用于信息获取的平台(如 B 站、微博等)的关注数量控制在 100 以内,如果新增则筛选优化之前的关注,减少无关内容的干扰。在完成上述行为的基础上,我使用 RSS 订阅这一似乎有些古早的方式,但是仅订阅了不到 50 个网站,其中大部分是博客或是个人网站,且会定期筛选,减少自己每天的 feeds,但几乎在这一 feeds list 中的文章都会扫一下标题或初步浏览一下。

这一点我最开始是自己搭建了 Miniflux 服务来抓取,并且用一个 RSS-to-Telegram-Bot 来推送提醒的,而最近开始使用 Readwise Reader 后,由于体验很好,便把这一部分迁移过来了。我使用的是 Readwise Reader 内置的一种管理模式,分为三类:
- Later
- Shortlist
- Archive
我会每天扫描一下 Feeds 面板,扫到感兴趣的文章会加入到 Later 中,作为一个稍后读,当然,就以前的经验来说,稍后读放久了常常会变成“稍后也不读”,所以我在筛选时非常克制,仅将很感兴趣且有时间后马上会读的文章加入,并要求自己在晚上的时候清理 Later 列表。
而我们也会在社交媒体互联网的各个角落被推送到一些信息,其中我尤其在意的是这几类:
- 感兴趣的一些观点/推文 threads
- 感兴趣的文章
- 有用的资源
如果是一些比较有意思的观点或是评论,我通常并不会加入软件的对应 List、收藏夹等,而是会复制其内容到 Logseq 的 Journal 中并打上对应 tag,其实这一步很多软件(包括 Readwise Reader)提供了推特 threads 保留或是其他的一些更方便保存推文的方式,但我倾向于自己复制和整理,以几句话的方式记录下来而不是仅仅存一个链接,这样似乎刻意增加的步骤会让我多一步审视这些观点,避免被强引导性或是情绪化的观点所影响,也更有益于自己消化信息并内化为自己的想法。
如果是自己感兴趣的一些文章,则会通过 Readwise 的 Chrome 插件进行阅读或保存。这部分我给自己的要求是每篇文章都要打上标签和 notes,notes 中主要描述为什么要读这篇文章。
其中如果仅仅是需要泛读或是获取信息的一些文章,我会加入 Later 列表,而精读的我则是会加入 Shortlist,并且必须要对其中一些有意义的话加 highlights,也尽量对 highlights 加上自己的一些评价和想法,这些都可以在插件中直接操作,很方便。

而如果是一些有用的网站、文档、代码、软件或是其他资源类的信息,我会使用 Pinboard,一个很古早但是很好用的书签管理工具来保存,同样是用浏览器插件进行保存,也会打上标签和简单的描述,大概一年左右了我积累了 455 个书签,其中大部分我都能够通过 tag 和名称在需要用的时候快速检索到。
而像是视频网站等我更多还是使用点赞或是收藏的方式,一方面对创作者表示支持,另一方面也通过一些自动化工具同步到我的 Telegram 个人频道「Yu’s Life」,并标记上对应 tag,但大多视频的信息效率并不高,所以更多是一些有趣的或是探索向的。
聚焦阅读
除了上述这些被动推送的一些信息流外,其实我们也还会有很多特定主题或是与自己的领域强相关的一些信息需求,这需要我们去主动阅读一些书籍、报告等。
这一部分我原本更多是使用 kindle 或阅读纸质书,并手动在 Logseq 进行一些记录。但是在 Randy 推出 Notepal 工具后,我开始使用微信读书,它本身有很多可阅读的书籍资源,并且我也用它导入 mobi 或是 epub 格式的一些书籍,阅读体验感还不错。

并且也很方便做一些笔记和标注,由于全平台同步,可以很方便地定期通过 Notepal 浏览器插件同步到 Readwise 中,效果也很好(上图就是同步过来的),这样也更有动力在碎片的一些时间里阅读一些书籍。
信息管理
上一节我对信息获取的渠道和系统进行了一些梳理,但这些依然还是零散的信息,如果要让它们成为自己知识和思考的一部分,依然需要更多整理、消化与沉淀的过程。但涉及那么多平台,搜索和整理并不方便,也比较难建立起信息之间的关联,受正在读的这本「Building a Second Brain」 启发,我主要做了如下两点:
- 借鉴和改造了 P.A.R.A 作为自己的全局 Tag 分类系统
- 使用 Logseq 和 Heptabase 构建 Second Brain
全局 Tag 系统

其中 P.A.R.A 是作者所提出的一个框架,分别是:
- Projects,正在做的项目相关
- Areas,特定领域
- Resources,未来可能会用到的资源
- Archives,已完成的项目
我在这四个的类型的基础上增加了一个「Thoughts」,用于归类我的一些随机的想法。
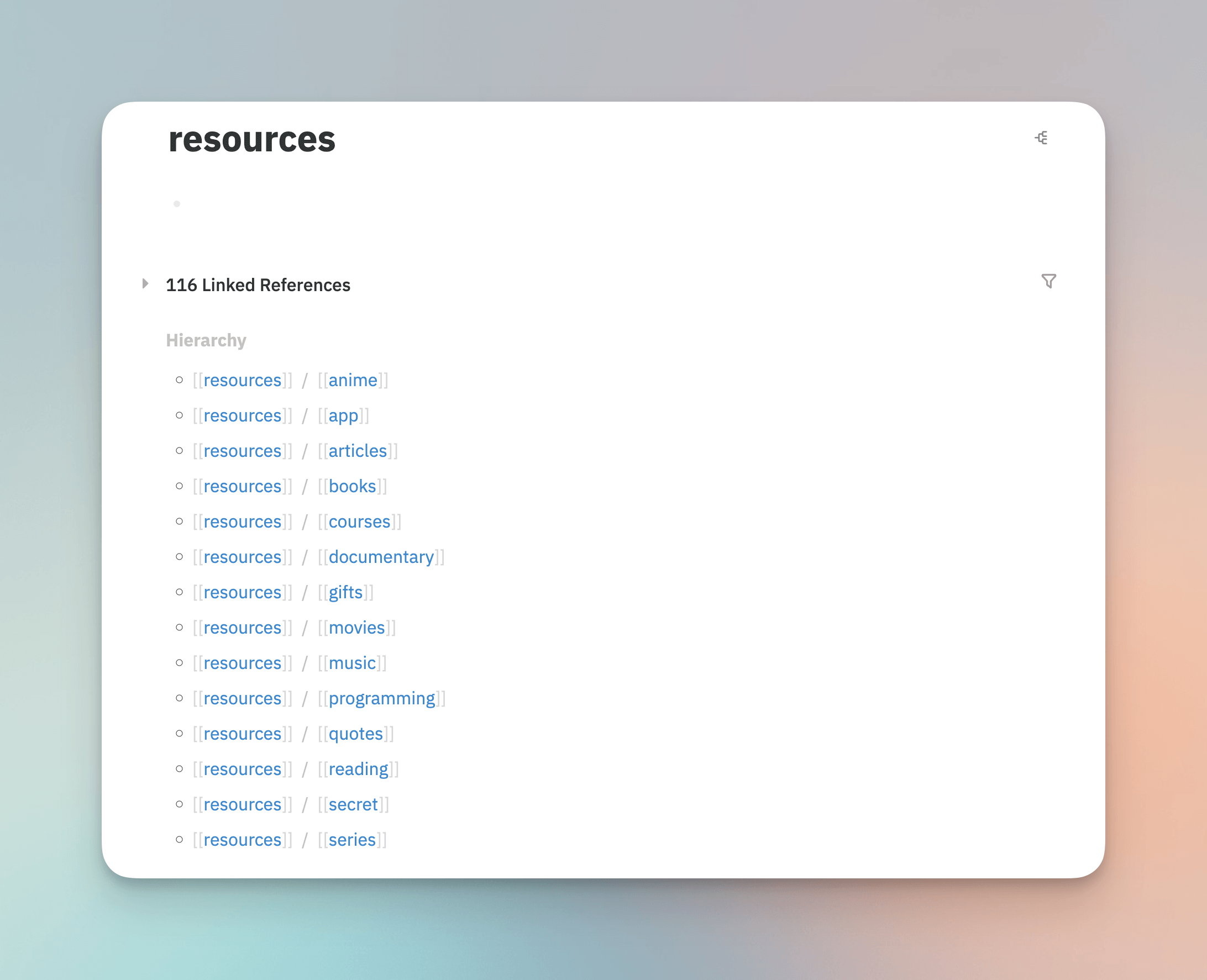
我的实现思路是把这五个类型作为我的全局一级 Tag,而更具体的一些项目、领域、行业可作为二级、三级 Tag,例如 Projects/writing/pkm,Areas/blockchain,Thoughts/weekly-review 等,Logseq 提供了很强大的多层 Tag 系统,会自动根据 / 进行分层,便于检索,分类也一目了然,我把之前现有的一些 Tag 修改后效果如下:
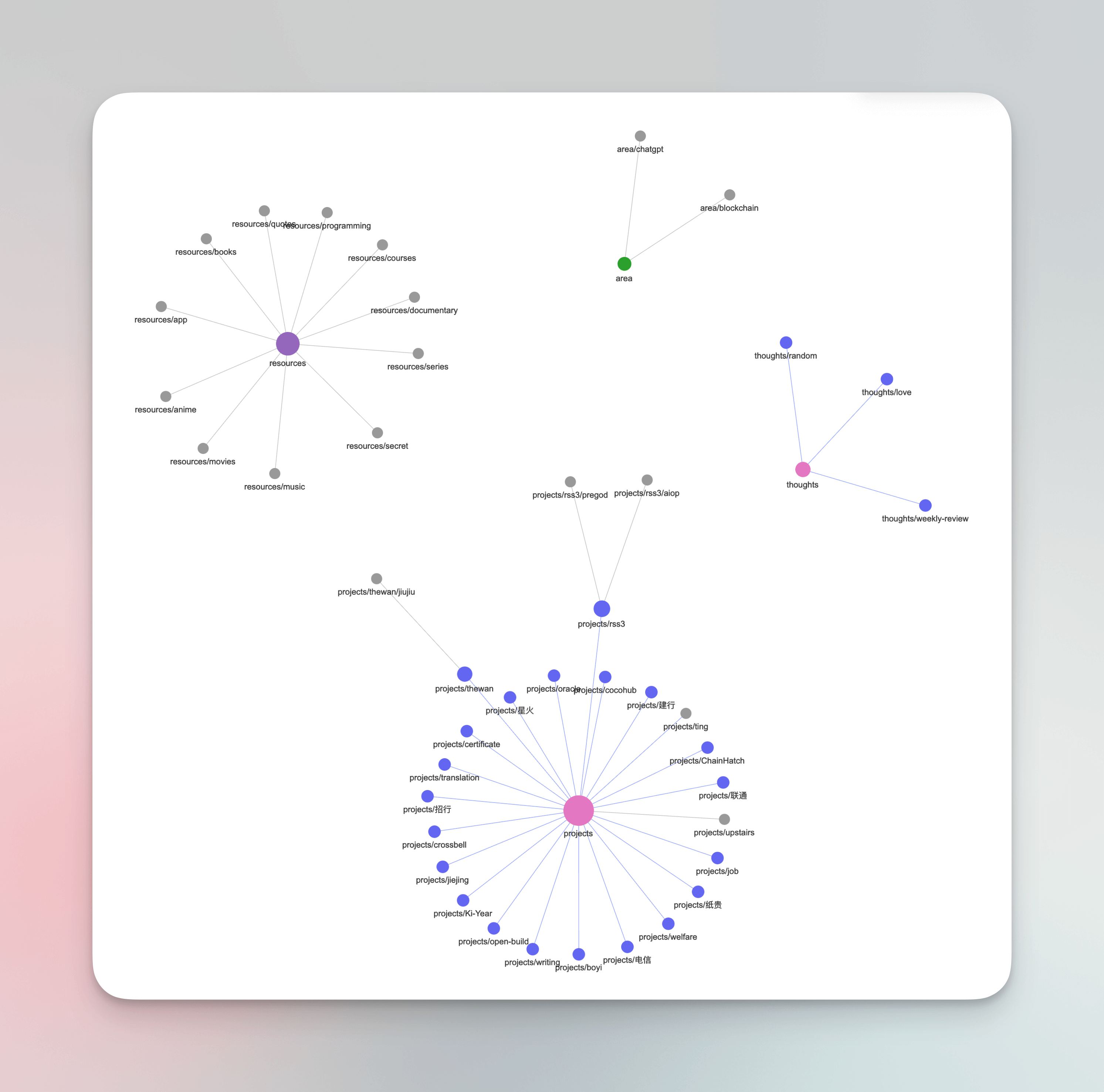
基于 Heptabase + Logseq 的 Second Brain
我之前一直都是使用 Logseq 作为自己的知识管理系统的,最近看到了 P.J. Wu 吳秉儒 入职 Heptabase,对这一平台有了更多了解,于是将其纳入自己的知识管理系统,和 Logseq 双刀流共同构建自己的第二大脑。只要因循上文所说的 Tag 系统,两个平台之间并不需要额外的关联便可以各司其职地进行信息管理。

其中,Logseq 作为兼具简单任务管理和双向链接的笔记系统,非常适合沉淀我上述的这些信息流和一些自己阅读后产出的初步想法,如高亮、评论 notes 等,由于 Logseq 有 Readwise 官方插件,可以很方便地将我在微信读书和网络文章中的高亮和笔记自动同步为 Logseq 的 pages,并通过时间与 Journal 关联,这样我在每天/每周写一些回顾时能很直观地看到我过去的阅读和想法,如上文就是我在阅读 枫影 Justin Yan 的这篇「每个人每天都只有 24 小时,希望我的选择真的是我的选择」时在他的网站上使用 Readwise Chrome 插件做的一些高亮和笔记,自动同步到了 Logseq 中,并根据我的配置打上了一些 tag 与属性。
Logseq 很适合做一些信息整理和回顾,但当我要对某个领域/概念进行调研、阅读书籍整理脉络或是输出一篇博客文章时就显得稍稍有些单薄,它的信息以 block 为单位散落在每一天的 Journal 中,通过双向链接或是 tag 进行关联跳转,不方便进行一些直接的可视化关联,也需要自己对在前期就对关键词和 tag 做到足够清晰,依然有一些心智负担,所以这一部分我使用 Heptabase 来进行管理。
Heptabase 可以看作是一个功能完善的白板笔记工具, P.J. Wu 吳秉儒 有很多关于 Heptabase 的高质量介绍文章,可以阅读了解一下。简单来说,它主要分为以下三个层级:
- Map
- Whiteboard
- Card
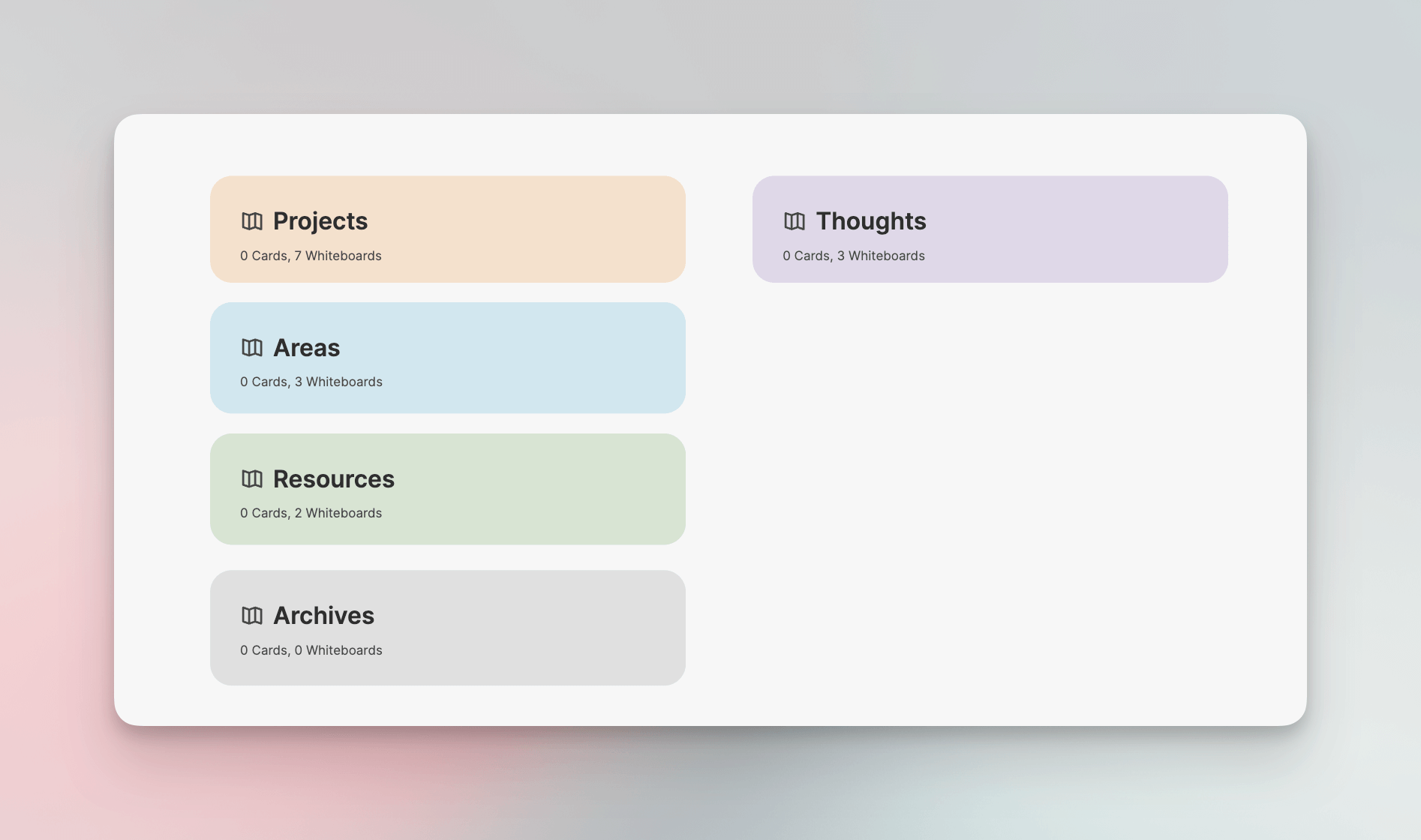
其中 Map 可以看作是我们 Second Brain 的整个空间,里面可以装各种白板,我建立了五个白板来作为第一层级 Tag。
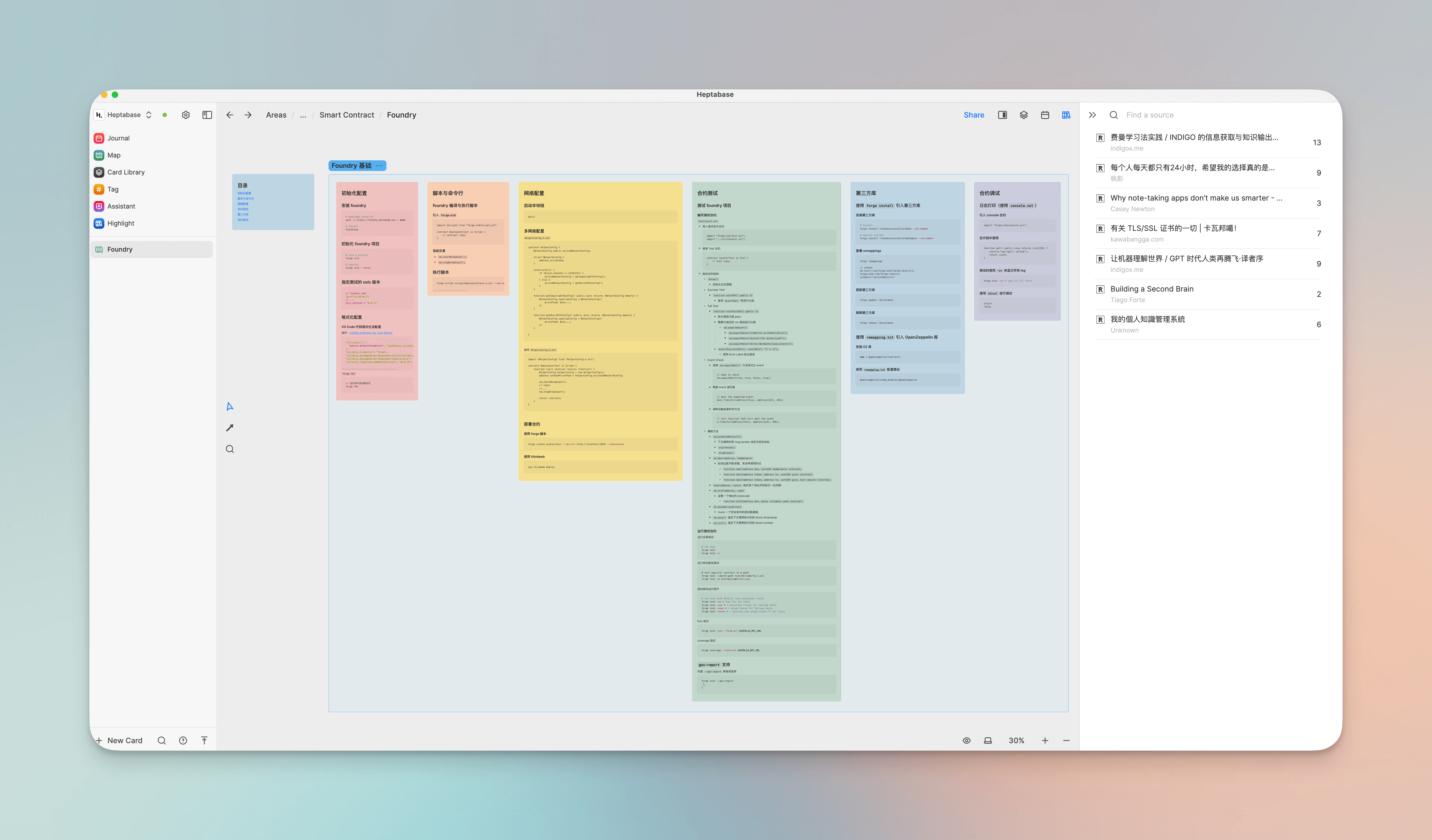
卡片代表的是我们脑中的一个个想法或是一些独立的信息点,我们可以通过卡片与卡片的关联,白板与卡片之间的层级来组织我们知识。
当我在写 Foundry 智能合约开发框架的教程时,我首先把一些零散的知识点或是实践中遇到的一些经验、教训以一个个白板平铺在 Foundy 的白板上(其为 Projects - Blockchain - Smart Contract 下的第四级子白板),当某个知识点已经足够多时,我会把白板之间再作一些 Section 分组、画线关联等。
其中它还提供了原生与 Readwise 的集成,可以在右侧边栏直接选择 Readwise 中我们对某些文章、书籍的一些 highlights 与 notes 作为卡片直接引入到白板中,为它们建立一些关联,很像我们人脑整理零散信息或是头脑风暴的过程,完美符合了我的需求。
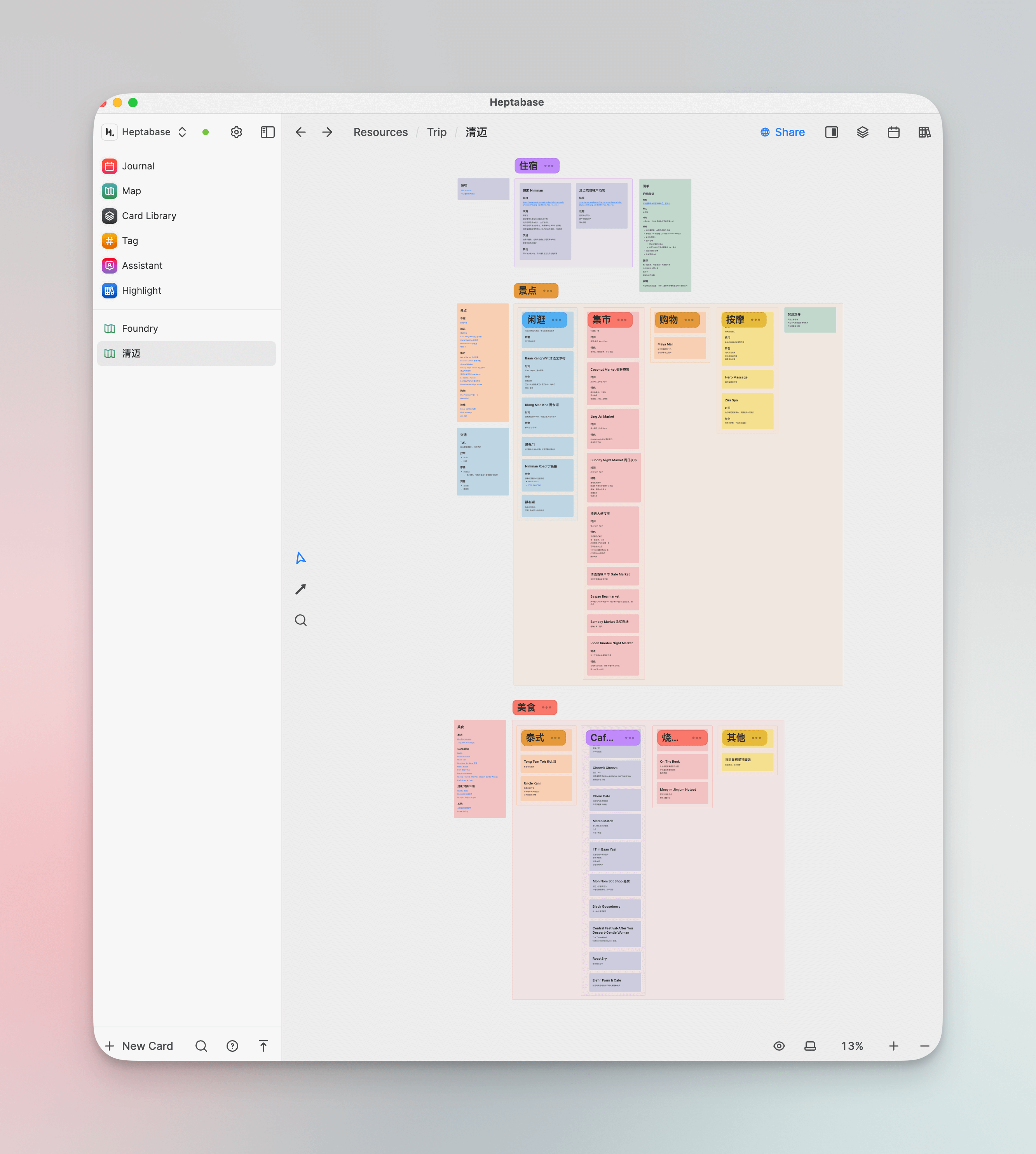
我目前还会用它做一些旅行攻略,把从小红书和其他人的攻略帖中的信息点作为一个个 card 放在旅行规划的白板中,然后再通过关联和分组进行整理,很规整。
信息输出
而我的输出则主要包含以下几个部分:
- 笔记/观点/日常
- 长文
- 主题研究
- 信息流
笔记/观点/日常
其中 Twitter 「pseudo_yu」是我最主要的无结构化的信息输出渠道,有时候是一些关于新技术的想法、关于工作的感受、与朋友相见的心情或是一张可爱的猫猫图,都构成了我输出,也对应着我输入中那些随机想法的快速产出。
其中,Twitter 上认识的朋友也给我带来了很多温暖。
长文
而我最重要的输出平台是个人博客「Pseudoyu」,目前周报是我的主要出口,偶尔也会有一些主题或专题性的关于技术或是效率工具的博文。
主题研究
输出一篇博文由于要考虑到受众、言辞表述与完整性等,其实有一定的心智负担,且周期较长,而我在进行特定领域的主题研究过程中大多把学习资料和一些 Demo 放在 GitHub 仓库中或是 Logseq 的某个笔记角落,有时候时间久了就得要重新学习了。而我现在更多放在 Heptabase 的一个白板里,能够存放很多小的知识点并且在后续的创作中再进一步归纳和精炼,所以其实可以在初具框架后把这个白板共享出来,可以与更多人进行交流,也能对同样在学习的朋友有所帮助。
信息流输出
我搭建了一个自己的 n8n 同步服务,采集我零散在各个平台的信息输入输出,并且还会将我对电影、书籍的观后感以及自己其他一些所思所想发在自己的 Telegram 频道「Yu’s Life」里。也关注了一些频道和群组获取一些资讯或是认识一些志同道合的人,偶尔会手动转发,主要同步以下几个平台:
- Blog,现在更像是一种生活日志。
- YouTube,也是重度用户了,看技术相关教程和数码资讯比较多,偶尔也有很多好玩的内容。
- Bilibili,主要保留了自己这么多年一直在关注的一些博主,看旅拍比较多,只看动态不看首页和热门。
- Pinboard,书签和网站保存管理工具,重度依赖了。
- Instapaper,管理稍后读,主要是一些精品或是长文的保存。
- GitHub,也是日常刷了,看一些好的项目,也用列表在管理 Star。
- Spotify,好听的歌会标注一下。
- 豆瓣,记录自己的书籍、剧集、电影、动漫和游戏,也是重度使用了,也在尝试每一个看过/玩过的作品都写一下自己的评价。
数据备份
虽然像是 Twitter、Telegram 已经是比较大的平台,但毕竟是中心化的产物,再加上最近的各种风波,对于自己这些信息源的归集总是不放心 Telegram 作为最终站,尤其是我常常在删消息时差点误点删除全部(奇怪的交互体验),所以信息的同步导出部分也是很重要一环,我使用 Crossbell 生态下的 xLog 与 xSync 服务进行我的博客与各平台信息的链上备份。
xLog
视觉效果和体验感都不错,且基于 Crossbell 地址能够很方便地进行 follow 和评论,包含了 NFT 展示柜、个人作品集等功能,这是我的 xLog 访问地址,有兴趣的朋友们也可以关注一下,不过目前出于定制化程度、各种历史文章迁移路由问题、自己各项数据统计服务变动等考虑,还是更多作为一个同步分发渠道。
xSync
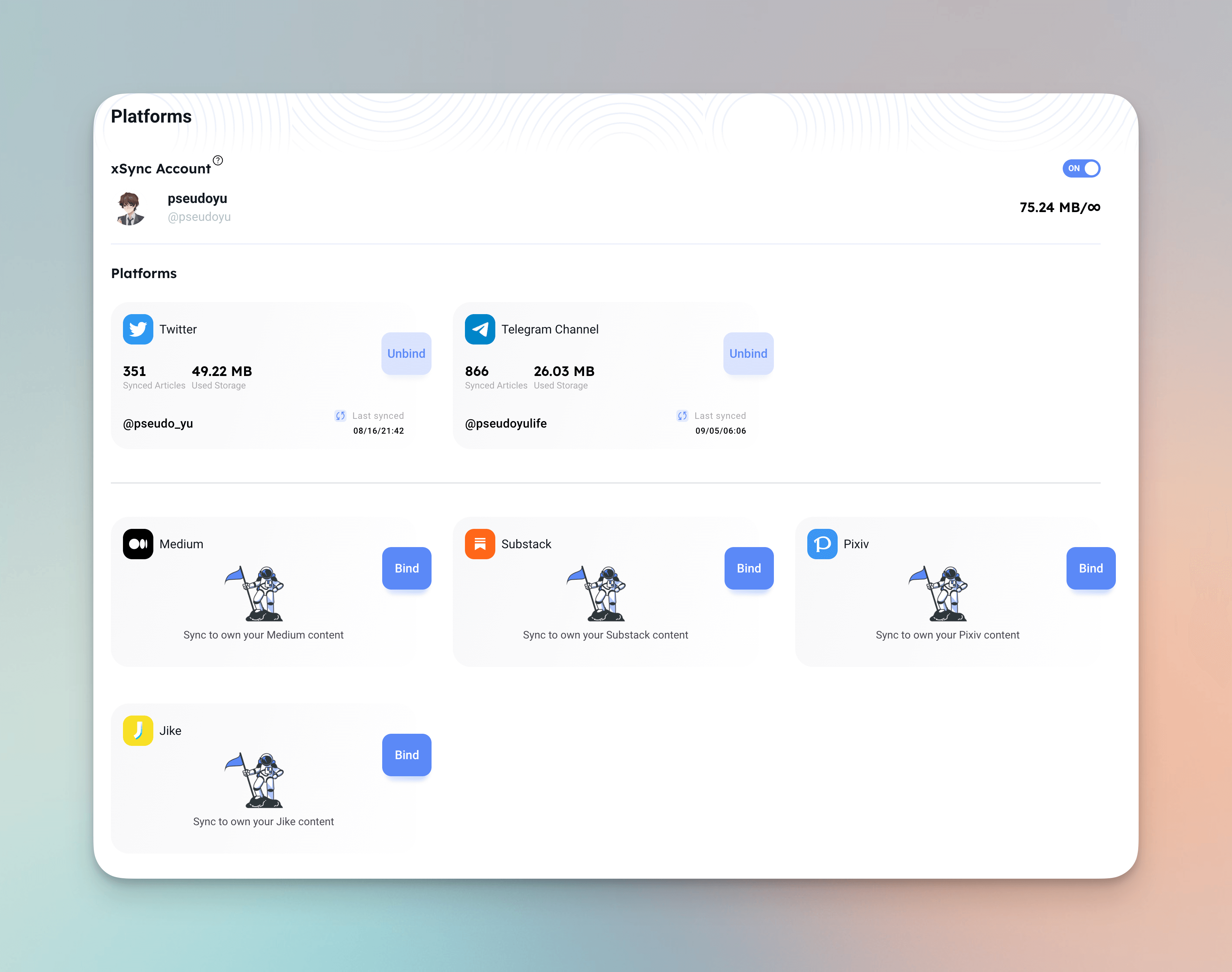
xSync 能够同步 Twitter、Telegram Channel 等平台,不需要做任何侵入式改造就能把我的聚合频道作再一次备份与存档,后续可以通过 xChar 来查看自己的各项消息了,很完美的解决方案,这是我的 xChar 个人主页: xChar,也可以通过 xFeed 查看我的信息流。
总结
it is probably a mistake, in the end, to ask software to improve our thinking.
Casey Newton 在最近的一篇「Why note-taking apps don’t make us smarter」中如是说。确实,这些系统或是工具软件其实终究只能辅助我们进行信息管理和输出,并不能代替我们思考,但构建知识管理系统在取悦自己的同时,也能够让思考变得更加高效,悦己才能达人,从而产出更有价值的输出。
希望这篇文章能够对大家有所帮助。